Análise de um dataset de terminologia de dados explorando três bibliotecas de visualização
Por
Juno Takano
Última atualização
14 de dezembro de 2023
Visão geral das relações entre os termos do Multilingual Data Stewardship Terminology
Introdução
O universo do desenvolvimento de software é saturado de termos carregados de importância mas com vidas muito curtas, ou onde é difícil enxergar a diferença entre relevância e ruído. Isso impacta decisões — pessoais ou institucionais — sobre onde investir recursos ao aprender, pesquisar e ensinar tecnologias.
Como conseguir analisar e representar visualmente a relevância de elementos de uma amostra que muda tão rapidamente? E será que ela muda tão rapidamente? Onde é a superfície e onde está o espaço mais profundo desses campos semânticos?
Sem intenção de dar uma resposta definitiva mas com interesse em explorar ferramentas, optei por uma perspectiva iterativa e que pudesse ser facilmente documentada e reproduzida.
Para isso, escolhi como ferramenta principal a linguagem R e o sistema de publicação Quarto. Dessa maneira, foi possível usar um só ambiente para fazer a importação, limpeza, análise, visualização e ainda a exportação desse processo para uma página web apresentável.
O dataset utilizado foi o SSHOC Multilingual Data Stewardship Terminology, um conjunto de definições ligadas à ideia de Data Stewardship, que pode ser traduzida como gestão ou administração de dados.
Entre os termos mais relevantes, segundo as métricas desenvolvidas, destacaram-se (em tradução livre) metadado, conjunto de dados, dados de pesquisa, sujeito de dados, dados pessoais e dados brutos. Continue lendo se deseja saber mais sobre os resultados do estudo.
Atalho
Abaixo você encontra um relatório técnico detalhado, com todo o código executado para processar e analisar o conjunto de dados.
Se prefere ler somente as conclusões resumidas e acionáveis, salte para o final. Se quiser ver apenas as visualizações mais relevantes, pode começar pela categorização ou ir diretamente para a seção 5.
Frontini, Francesca; Gamba, Federica; Monachini, Monica and Broeder, Daan, 2021, SSHOC Multilingual Data Stewardship Terminology, ILC-CNR for CLARIN-IT repository hosted at Institute for Computational Linguistics “A. Zampolli”, National Research Council, in Pisa, http://hdl.handle.net/20.500.11752/ILC-567.
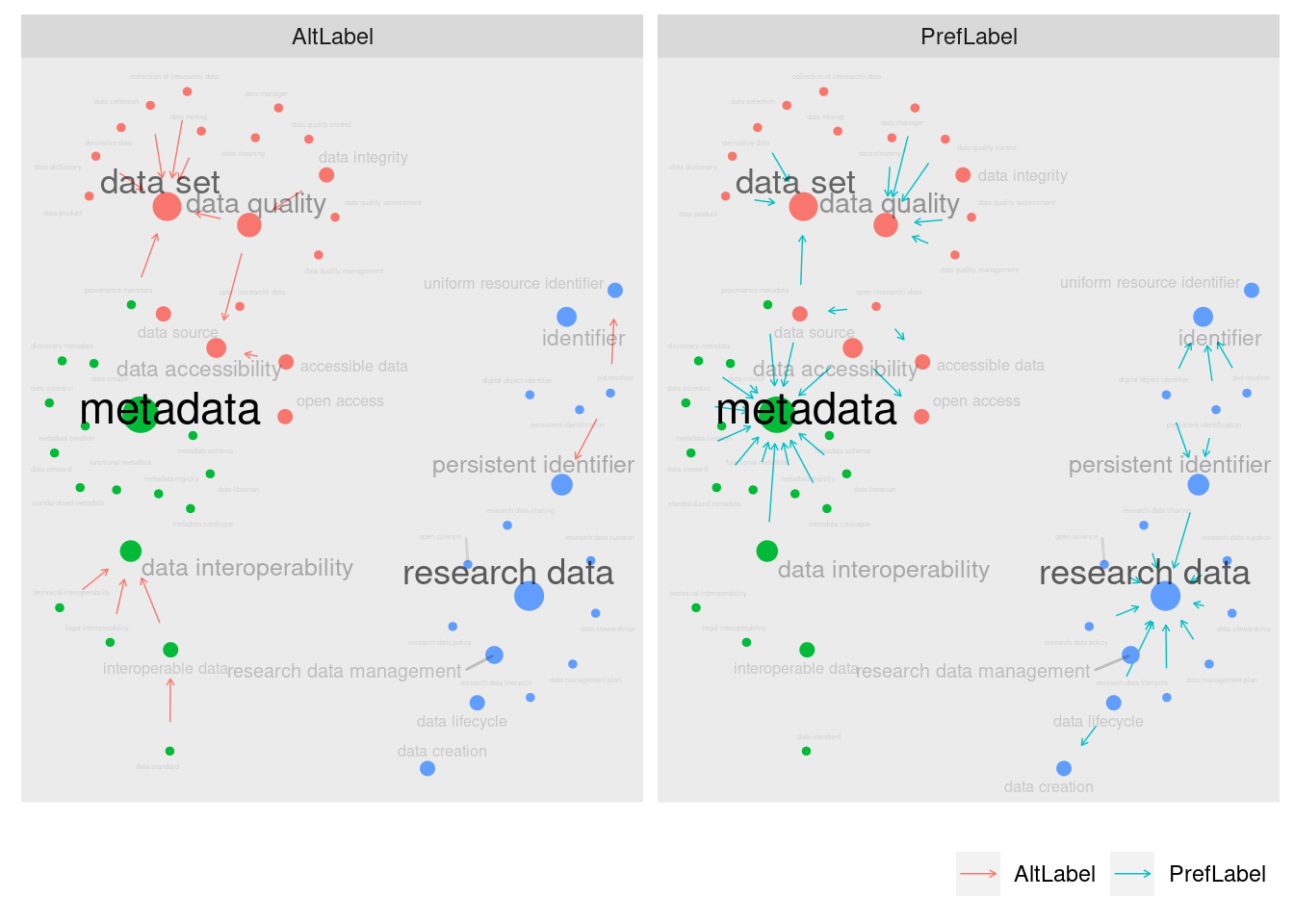
Para quantificar a relevância de um termo em relação aos demais, foi usada uma métrica aqui chamada de popularidade.
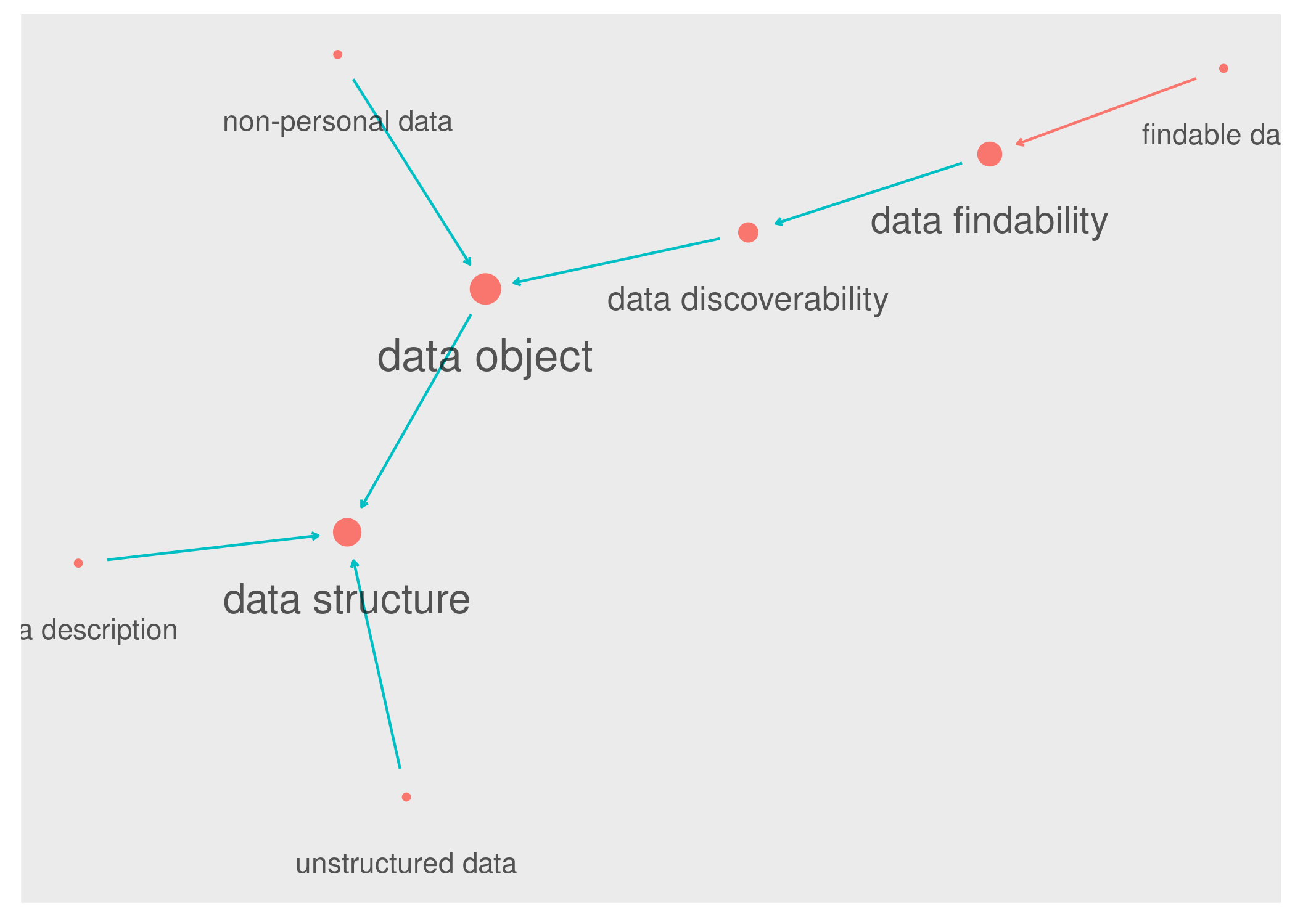
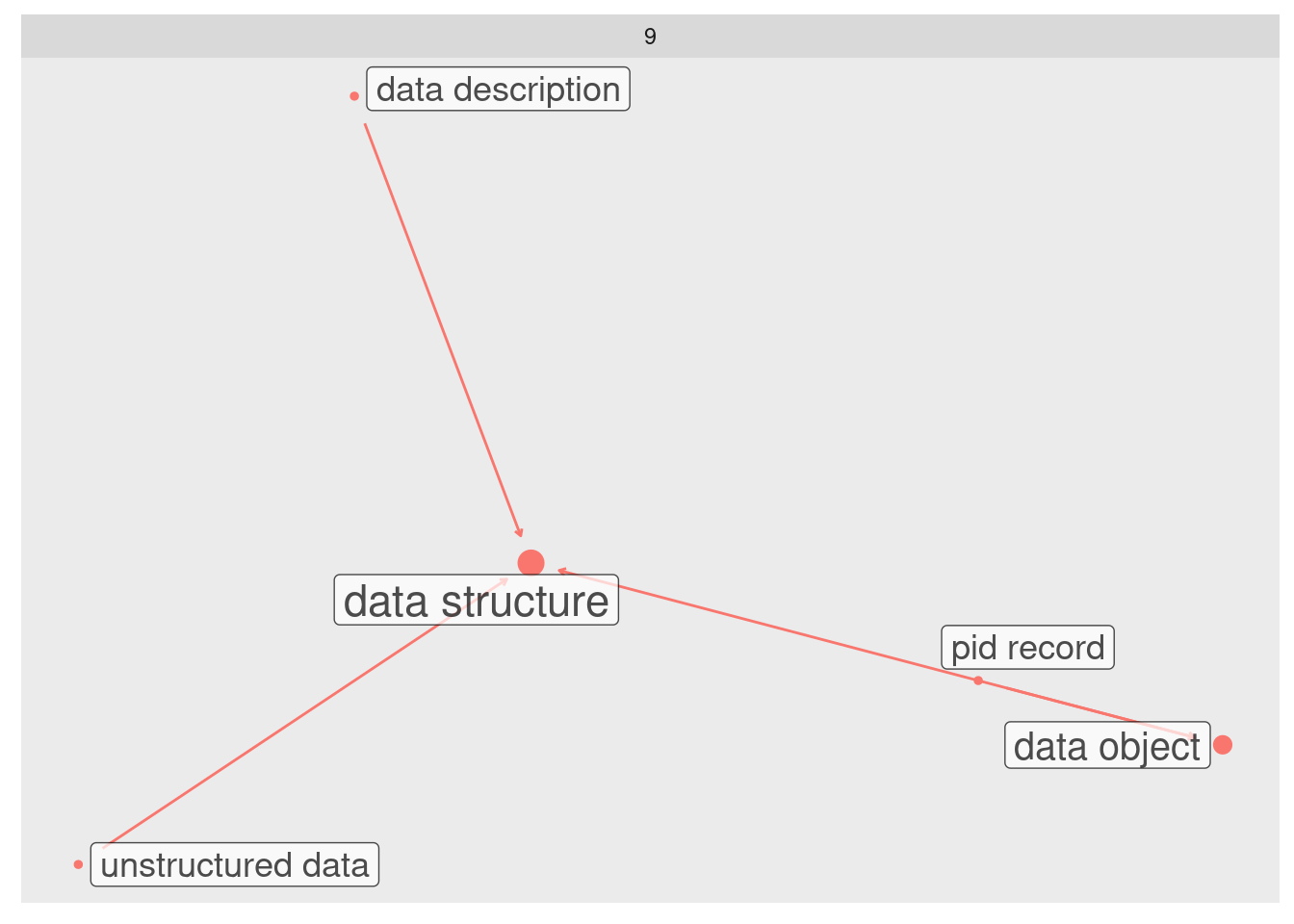
O grafo é uma rede de elementos (chamados também nós ou nodes) que estão conectados por ligações (chamadas também de links ou edges).
Exemplo de um grafo simples.
No exemplo de grafo acima, o nó data structure recebe três ligações e tem portanto um valor de popularidade 3. O nó data object, por sua vez, recebe apenas duas ligações e tem popularidade 2.
Trata-se da quantidade de vezes que um determinado nó (cada elemento da rede de conexões) recebe uma conexão. Para esse estudo, uma conexão representa uma menção daquele termo na definição de outro.
Por exemplo, vemos abaixo a definição de data security:
“Result of the data protection measures taken to guarantee data integrity.”
Ao mencionar tanto data protection quanto data integrity, as relações são estabelecidas através do mapeamento feito usando as ferramentas da linguagem R.
Para esse estudo, não foram considerados termos no plural nem suas diferentes formas decompostas, apenas as junções exatas do termo. Contudo, foram levadas em conta todos os termos alternativos do conjunto de dados, na forma das AltLabels.
Isso significa que um termo pode ter mais de um nome, como por exemplo ocorre com o termo data publication. Ele tem as AltLabels data publishing e publication of data. Qualquer uma delas, se mencionada na definição de outro termo, estabelece uma relação.
Para grifar essa diferença, ao longo do estudo foram utilizadas diferentes cores ou formatos de linha para representar as diferentes relações entre cada termo.
2. Preparar
Nesta etapa, os dados são carregados e preparados para o processamento.
O arquivo de dados original é disponibilizado no formato csv e tem uma estrutura de dados longa. Isso significa que um mesmo ID se repete em diferentes linhas. Será preciso converter essa estrutura para uma forma ampla para que os dados possam ser manipulados e plotados.
A preparação envolve ainda observar a confiabilidade dos dados. No conjunto original é possível ver que há múltiplas fontes possíveis para os dados. Na demo oficial do projeto também é possível ver o cruzamento das informações em um formato mais legível.
Acima, vemos uma busca pela definição do conceito de “data stewardship”.
Data stewardship can be defined as the tasks and responsibilities that relate to the management, sharing, and preservation of research data throughout the research lifecycle and beyond.
Em tradução livre:
Gestão de dados pode ser definida como o conjunto de tarefas e responsabilidades que se relacionam à gestão, compartilhamento, e preservação de dados de pesquisa ao longo do ciclo de pesquisa e além dele.
3. Processar
Com os dados carregados, podemos dar início à limpeza.
Tentando usar o conhecimento obtido ao longo da certificação, optei por utilizar apenas a linguagem R para fazer todo o processo.
Além da limpeza, serão realizados aqui alguns processos de validação para verificar se os dados realmente estão limpos e se não há informações duplicadas ou IDs faltando, já que na etapa de análise será necessário criar métricas que dependem de uma sequência precisa e ininterrupta de IDs.
Limpeza
Cabeçalhos
Os cabeçalhos das colunas vieram em duas colunas separadas, sendo portanto importados incorretamente por padrão.
O código acima soma a quantidade de ocorrências de cada uma das quatro palavras. Um resultado TRUE significa que o total é igual ao total de linhas no dataframe (atualmente, 489).
Podemos agora separar as colunas usando apenas ID, tipo e descrição para a análise.
Para que o pivoting com pivot_wider() una as linhas com conteúdos diferentes mas categorias iguais (na coluna type) usa-se a instrução unnest(), que separa essas linhas novamente. Do contrário, haveria a perda de dados.
Este post no rdrr.io foi essencial para compreender melhor a solução.
O seguinte erro era gerado sem ela:
Warning: Values from `term` are not uniquely identified; output will contain list-cols.
* Use `values_fn = list` to suppress this warning.
* Use `values_fn = {summary_fun}` to summarise duplicates.
* Use the following dplyr code to identify duplicates.
{data} %>%
dplyr::group_by(concept_id, type) %>%
dplyr::summarise(n = dplyr::n(), .groups = "drop") %>%
dplyr::filter(n > 1L)
O que isso indica é que valores de coluna duplicados são, por padrão, unidos em listas para que não sejam perdidos na hora de juntar as linhas por seus IDs.
Agora vamos converter de volta para um dataframe:
mdst_pv <-data.frame(mdst_pv)
E finalmente temos um único concept_id por observação:
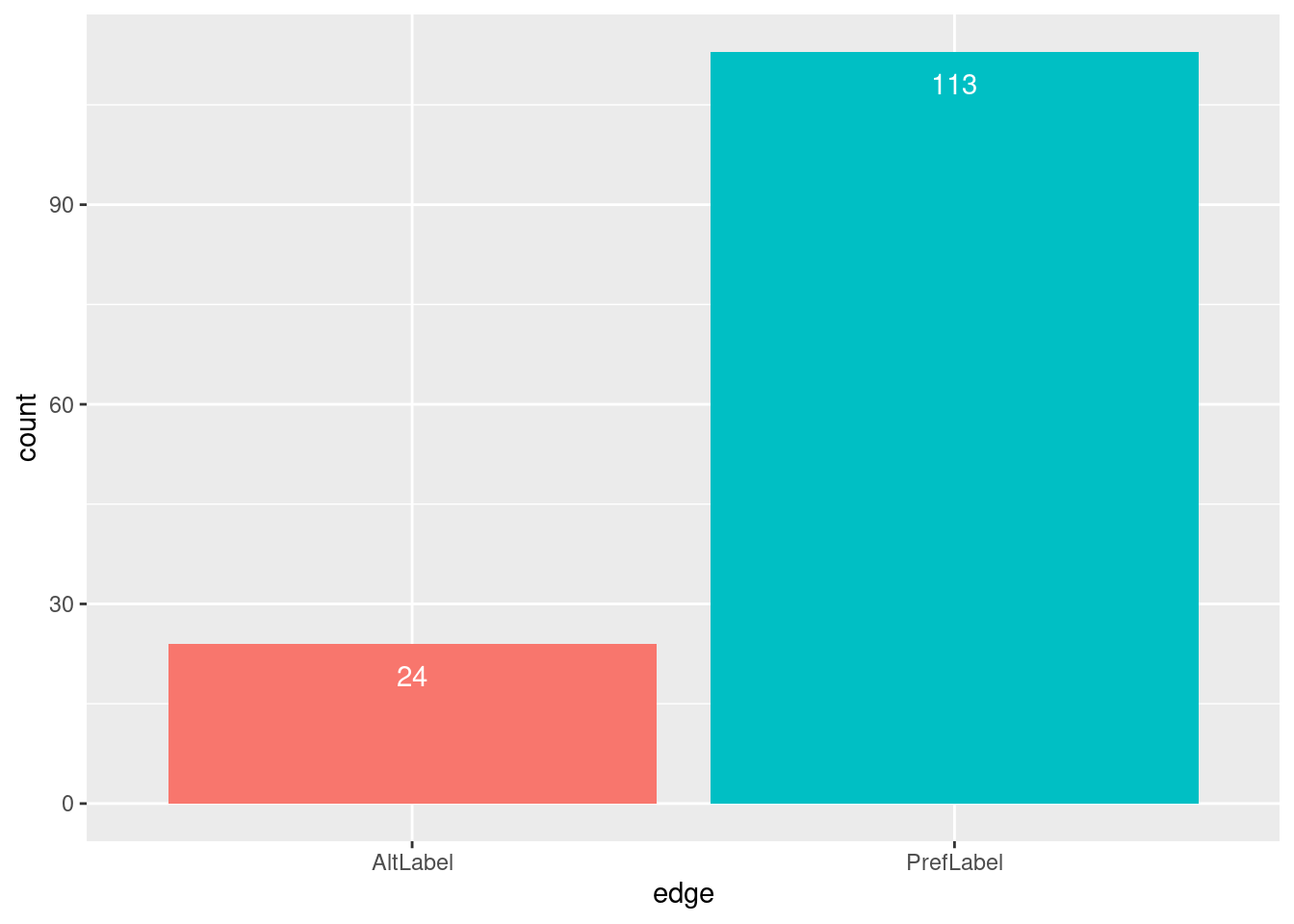
Nos metadados do conjunto há a informação de que são 210 conceitos. A página online informa 211 conceitos.
Abaixo foi feito um cruzamento dos dados em seu estado atual com os totais exibidos na página do SSHOC:
Coluna
Original
Atual
Diferença
concept_id
211
209
2
PrefLabel
211
209
2
Definition
211
209
2
AltLabel
61
73
-12
No nosso data frame atual temos 209 IDs, 209 PrefLabel e 209 definições, todos valores únicos. Faltam dois itens para cada.
O maior problema ainda são as AltLabels. Temos 70 AltLabels, o que significa que temos 12 AltLabels a mais. O que encontramos até agora removeria apenas duas AltLabels, deixando ainda outras 7. É possível que haja mais duplicações entre as colunas que foram separadas.
Se olharmos o último ID, ele é “version_control_211”:
tail(mdst_fl, 1)
Observando os dados para tentar entender a diferença entre os 211 IDs e as 209 observações, percebi que o número das linhas não batia com o dos IDs.
Por exemplo, os IDs 170 e 171 são pulados:
mdst_pv[168:173, ]
Olhando no conjunto original, eles também não constam:
E usei o somatório de 1 a 211 junto com um loop for para verificar se os números estão em sequência e não são duplicados. Isso também facilita encontrar exatamente onde está o erro:
for (i in1:211) {if (i != mdst_pv$id_no[i]) {print(paste(i, "!=", mdst_pv$id_no[i]) )break }}
Aqui parece ter faltado um concept_id para a entrada referente a “PID” e há ainda uma entrada faltando após essa, que seria do ID 171. Isso teve algumas consequências:
O campo Definition do ID orphan_data_169 ficou com sua própria definição e a de PID juntas
“PID” ficou como a AltLabel do ID orphan_data_169.
Inserção
Para alterar os dados da coluna Definition — atualmente do tipo lista devido a essa entrada duplicada — será preciso tipá-la como character:
mdst_ad <- mdst_pv %>%add_row(tibble_row(concept_id ="persistent_identification_170", PrefLabel ="persistent identification", Definition ="the act of identifying a resource via its persistent identifier.", id_no =as.integer(170)), .after =169) %>%add_row(tibble_row(concept_id ="persistent_identifier_171", PrefLabel ="persistent identifier", Definition ="a unique and stable denomination (reference) of a digital resource (e.g. research data) through allocation of a code that can be persistently and explicitly referenced on the internet.", AltLabel_1 ="pid", id_no =as.integer(171)), .after =170) %>%mutate(id_no =as.integer(id_no))
Conferindo se está tudo certo:
mdst_ad[170:171,]
Agora precisamos retirar a AltLabel e definição extras em orphan_data_169:
mdst_ad[169,] <-tibble_row(concept_id ="orphan_data_169", PrefLabel ="orphan data", Definition ="data that is not machine readable because the data exists with no identifiable computer application or system that can retrieve it, or the data is machine readable but does not have sufficient content, context or structure to render it understandable.", AltLabel_1 =NA, AltLabel_2 =NA, AltLabel_3 =NA, id_no =as.integer(169))
Vamos ver como ficou essa área novamente:
mdst_ad[168:172,]
Validação
Feitas essas inserções e transformações, podemos executar o teste criado anteriormente para validar que a sequência de IDs agora está correta.
Primeiro vamos reescrever a coluna id_no com os números da coluna concept_id, já que ela foi alterada:
for (i in1:211) {if (i != mdst_ad$id_no[i]) {print(paste("Erro no índice", i, "id_no:", mdst_ad$id_no[i], "ID:", mdst_ad$concept_id) )break } }rm(i); paste("Diferença:", sum(1:211) -sum(mdst_ad$id_no)) # 0
[1] "Diferença: 0"
Com os números dos IDs agora iguais aos números de cada observação, podemos remover a coluna id_no:
mdst_ad <-select(mdst_ad, !id_no)
Mais deduplicação
Antes de fazer mais validações, vamos remover qualquer caractere de espaço que esteja sobrando ou duplicado:
Sabendo que todos se encontram na coluna Definition, vamos encontrar quais foram elas usando a função setdiff():
setdiff(mdst_adt$Definition, mdst_ad$Definition)
[1] "formal document that outlines how to handle research data both during your research and after the research project is completed."
[2] "data modeling is the process of creating a visual representation of either a whole information system or parts of it to communicate connections between data points and structures."
[3] "the practice of making data available for reuse. this may be done, for example, by depositing the data in a repository, through data publication."
[4] "data stewardship can be defined as the tasks and responsibilities that relate to the management, sharing, and preservation of research data throughout the research lifecycle and beyond."
[5] "data storage is the recording (storing) of information (data) in a storage medium."
[6] "hierarchical data is defined as a set of data items that are related to each other by hierarchical relationships. hierarchical relationships exist where one item of data is the parent of another item."
[7] "online, free of cost, accessible data that can be used, reused and distributed provided that the data source is attributed."
[8] "the practice of making research data available for reuse. this may be done, for example, by depositing the research data in a repository, through research data publication."
A função retornou apenas oito resultados. Vamos inspecionar mais de perto o resultado anterior achando qual é o concept_id de cada uma das nove linhas encontradas:
Vemos aqui que o ID metadata_158 é o único a não ser encontrado na comparação com setdiff(mdst_adt$Definition, mdst_ad$Definition).
Podemos confirmar isso retirando o texto sem espaços extras do texto original e vendo se resta apenas um espaço.
O código a seguir usa a função mutate_all para criar uma tabela que mostra todas as colunas comparadas.
mdst_adc <- mdst_ad %>%mutate_all(list(~str_trim(., side ="both"),~str_replace_all(., " ", " ")))
A função mutate_all acima recebe uma lista de funções anônimas como argumento. O símbolo de fórmulas ~ faz com que o código fique mais limpo, evitando ter de declarar as funções como function .... Os pontos servem para capturar os argumentos passados pela mutate_all para cada observação do conjunto.
O resultado será um novo dataframe com novas colunas com o nome da função aplicada no final. Teremos portanto uma coluna “concept_id” com os dados originais, outra com “concept_id_str_trim”, e outra com “concept_id_replace_all” e assim por diante para todas as colunas.
Esse é nosso conjunto comparando todas as diferenças:
mdst_adc
Com base nesse conjunto, podemos tentar chegar às diferenças exatas entre as strings originais e suas versões limpas:
Essa função recebe um dataframe e uma coluna e cria um dataframe booleano com TRUE para duplicatas. Ela adiciona uma coluna com o número da linha correspondente e um filtro para retornar apenas os valores duplicados.
Vamos executar o teste na coluna Definition:
dup_check(mdst_adt, "Definition")
Ela indica que a linha 171 tem um erro de duplicação. Já trabalhamos nessa linha ao resolver a falta de informações. Essa descrição foi inserida manualmente nessa etapa, e está correta de acordo com o ID persistent_identifier_171.
Antes de mapear as relações, precisei entender qual era a estrutura que os dados deveriam usar.
Para isso estudei os exemplos e a documentação da primeira biblioteca, a ggraph, que utiliza alguns princípios da ggplot — abordados na certificação — para fazer visualizações de grafos:
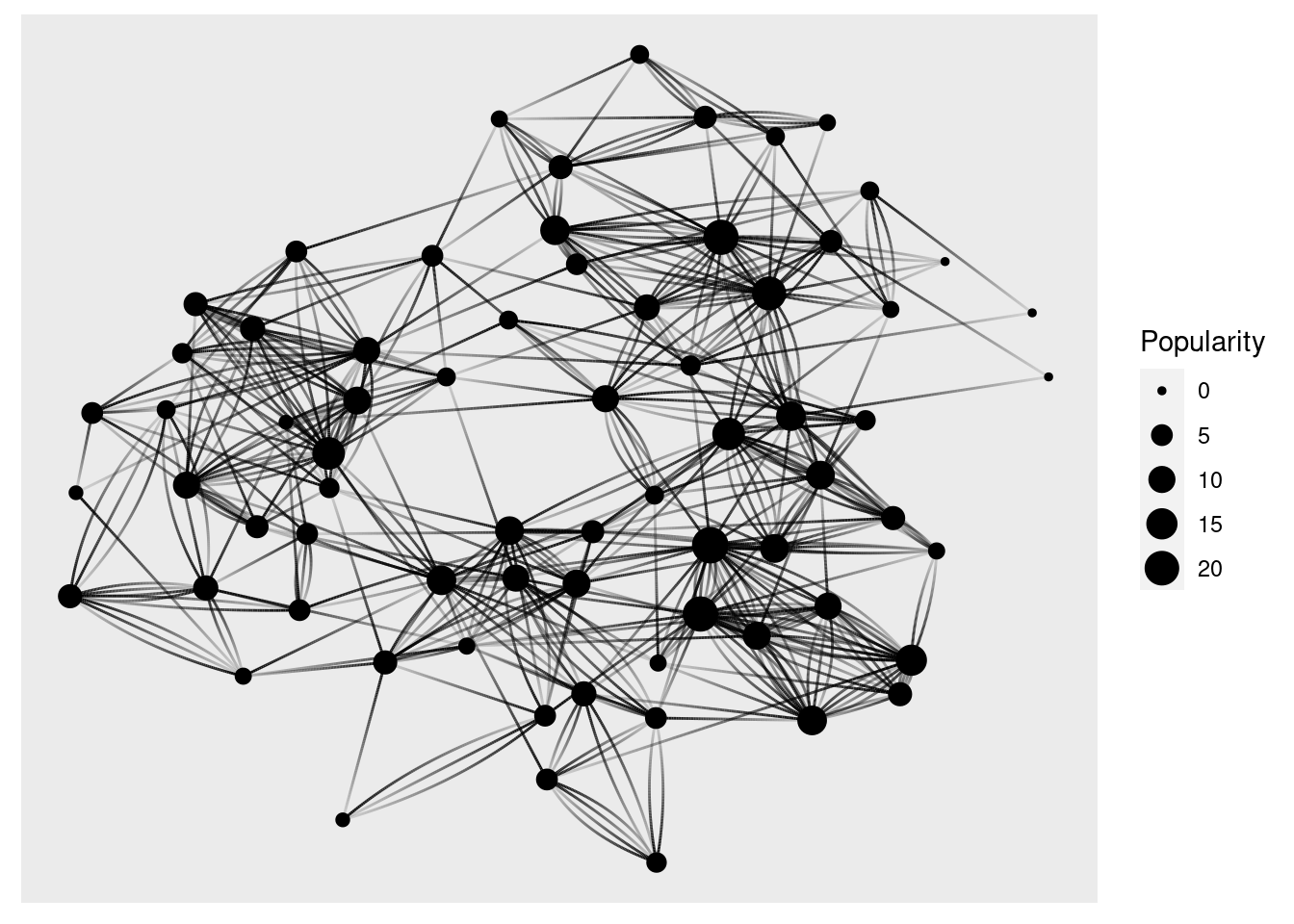
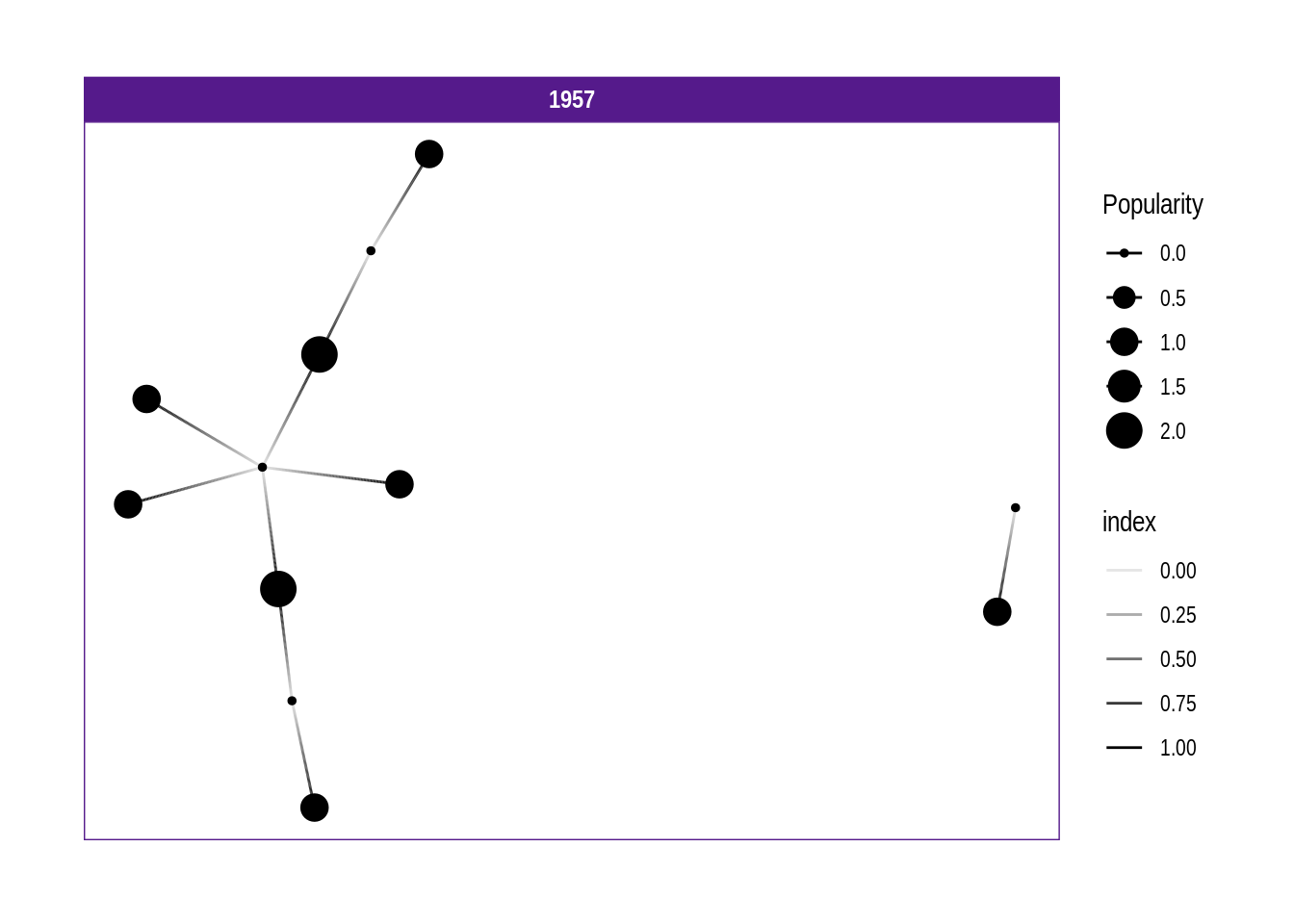
Analisando a coluna de popularidade, nesse ponto percebi que ela se refere à quantidade de vezes que um valor é mencionado na coluna “to”.
Se ordenarmos os nós pela popularidade, temos 15 e 21 no topo:
hs10_graph %>%arrange(desc(Popularity))
# A tbl_graph: 12 nodes and 10 edges
#
# A rooted forest with 2 trees
#
# Node Data: 12 × 2 (active)
name Popularity
<chr> <dbl>
1 15 2
2 21 2
3 14 1
4 54 1
5 55 1
6 22 1
# … with 6 more rows
#
# Edge Data: 10 × 3
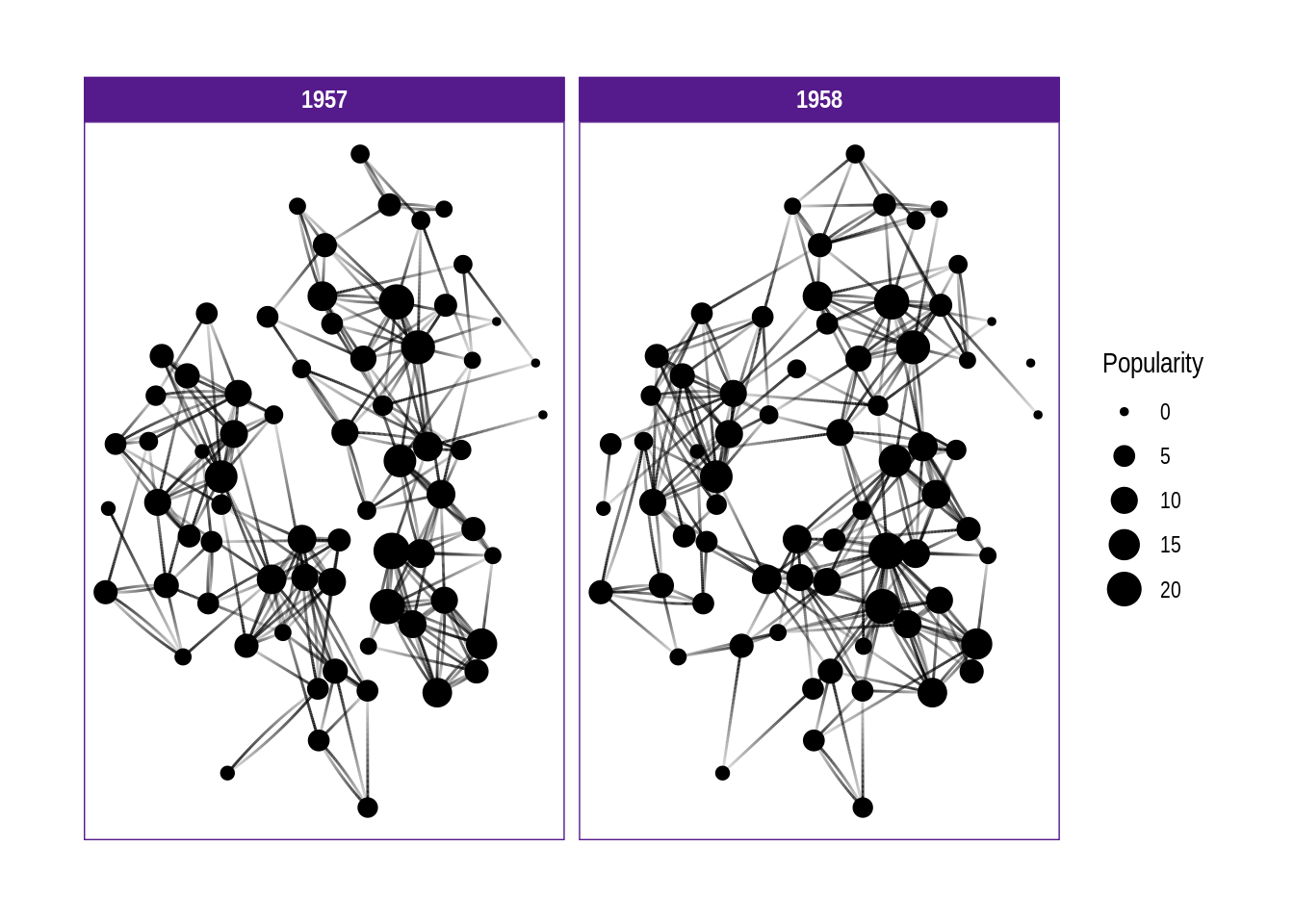
from to year
<int> <int> <dbl>
1 9 3 1957
2 9 1 1957
3 9 2 1957
# … with 7 more rows
Do lado direito, sozinhos, o ponto maior é 5, que recebe uma conexão de 4, e o menor é 4, que não recebe nenhuma conexão.
Isso também mostra que a parte transparente das linhas (edges) que conectam os nós é mais fraca na parte em que sai do nó. Isso é definido em geom_edge_fan(aes(alpha = after_stat(index))
Na página sobre Edges encontrei como tornar as linhas em setas e nomear os nós:
A visualização acima foi essencial para compreender a biblioteca através de um exemplo prático e reduzido, e confirmar as suspeitas descritas anteriormente.
A documentação sobre nodes da biblioteca ggpraph tem muitos exemplos interessantes. Para não perder tempo, porém, decidi primeiro transformar os dados do projeto para que pudesse fazer mais testes já usando eles.
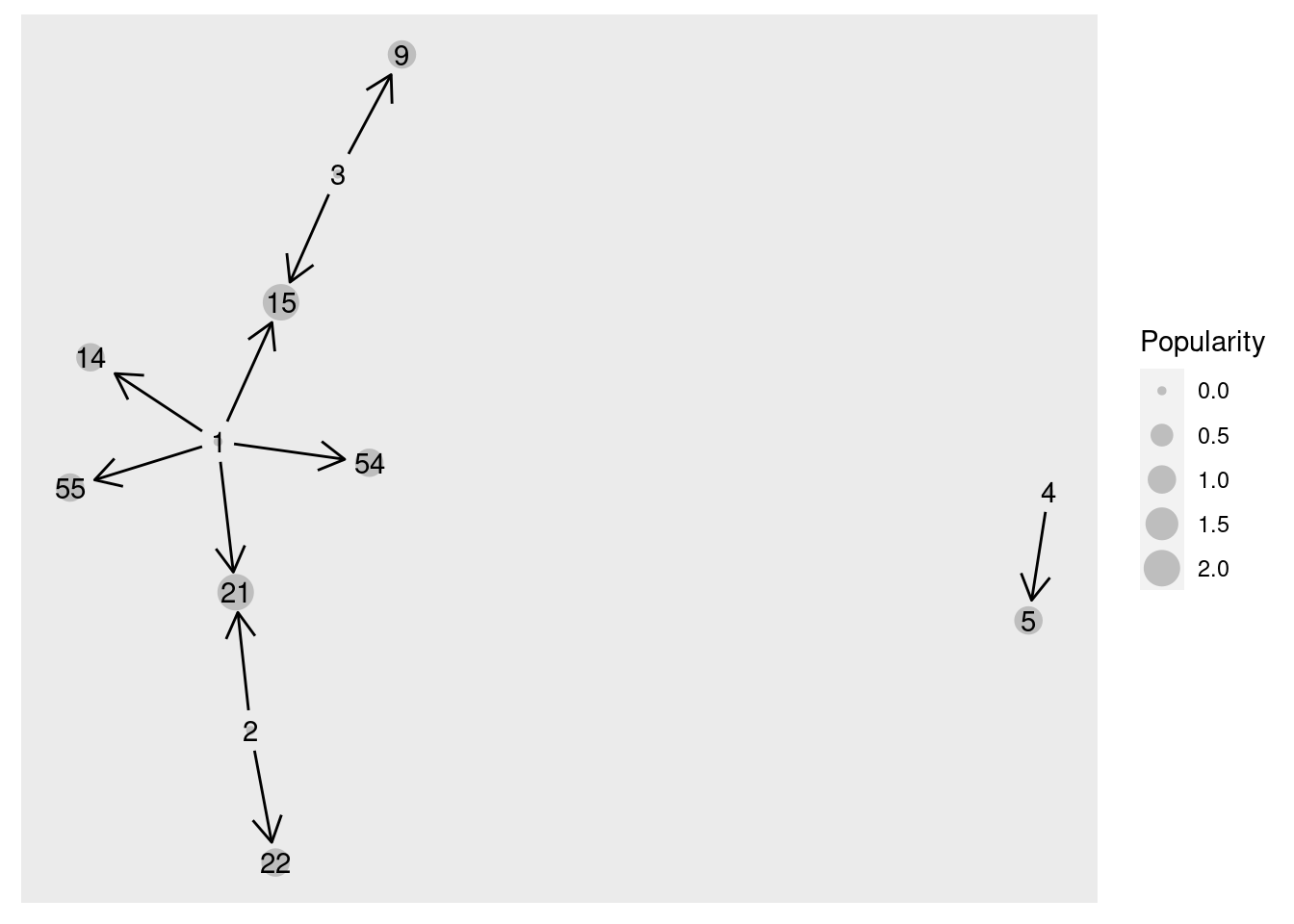
Agora já temos uma ideia de que tipo de esquema precisamos para usar a estrutura de grafo. Ele parece ser centrado nas colunas “name” (um “ID”), “from” e “to” (de/para), que indicam as conexões de saída e entrada, e uma coluna de “popularidade” que mostra o total de menções daquele ID na coluna “para”.
Mapeamento
Podemos começar limpando o ambiente. Vamos trabalhar com o conjunto “termos” como o resultado da limpeza feita até aqui.
Para podermos plotar um grafo e observar relações, será necessário então ter uma estrutura similar a essa:
# A tibble: 6 × 2
from to
<dbl> <dbl>
1 1 14
2 1 15
3 1 21
4 1 54
5 1 55
6 2 21
Mas para termos também a informação de que tipo de relação existe entre cada nó, seria preferível uma estrutura assim:
from
to
edge
1
14
PrefLabel
2
15
AltLabel1
3
21
AltLabel1
4
54
PrefLabel
5
55
AltLabel2
6
21
PrefLabel
7
34
PrefLabel
8
66
PrefLabel
9
11
AltLabel3
10
80
PrefLabel
A diferença entre PrefLabel e AltLabel é apenas uma possibilidade entre várias que podem ser usadas para determinar qual é a relação entre os dois termos. Neste caso, a diferença entre a AltLabel ser 1, 2 ou 3 é pouco relevante, então não será usada.
Outras relações poderiam ser relacionadas à semântica presente na frase, por exemplo, se o termo é mencionado na definição como “é” ou “não é”, como um “tipo de” ou “pertence a”, etc.
Aqui vamos utilizar um algoritmo simples que apenas conta a quantidade de menções de cada PrefLabel ou AltLabel e as adiciona em uma tabela de relações:
flowchart TB
a( ) -->
A{id = pair} -- T --> B[pair = pair + 1]
B --> Ae( )
A -- F --> Ae( )
Ae( ) --> C{pair contém \nPrefLabel}
C -- T --> D[adiciona a \nrelacoes]
D --> Ce( )
C -- F --> E{pair contém \nAltLabel}
E -- T --> F[adiciona a \nrelacoes]
E -- F --> Ee( )
F --> Ee( )
Ee --> Ce( )
--> z( )
Por exemplo, o ID discovery_metadata_141 tem uma definição que começa com “Metadata that are used for the discovery of data”. Essa definição contém a PrefLabel “metadata” do ID metadata_158.
Isso criará uma relação com origem (from) em discovery_metadata_141 e chegada (to) em metadata_158 com a relação (edge) PrefLabel:
from
to
edge
141
158
PrefLabel
Vamos criar o dataframe relacoes com uma coluna para a relação de origem (from), de chegada (to) e uma coluna para saber qual é o tipo de relação (edge), optando apenas entre PrefLabel e AltLabel.
relacoes =data.frame(to =0, from =0, edge ="none")str(relacoes)
'data.frame': 1 obs. of 3 variables:
$ to : num 0
$ from: num 0
$ edge: chr "none"
O código abaixo implementa o algoritmo mostrado acima.
Ele percorre nosso conjunto de dados e mapeia cada relação em uma nova linha, gravando o ID de origem e destino de cada menção de uma PrefLabel em uma Definition.
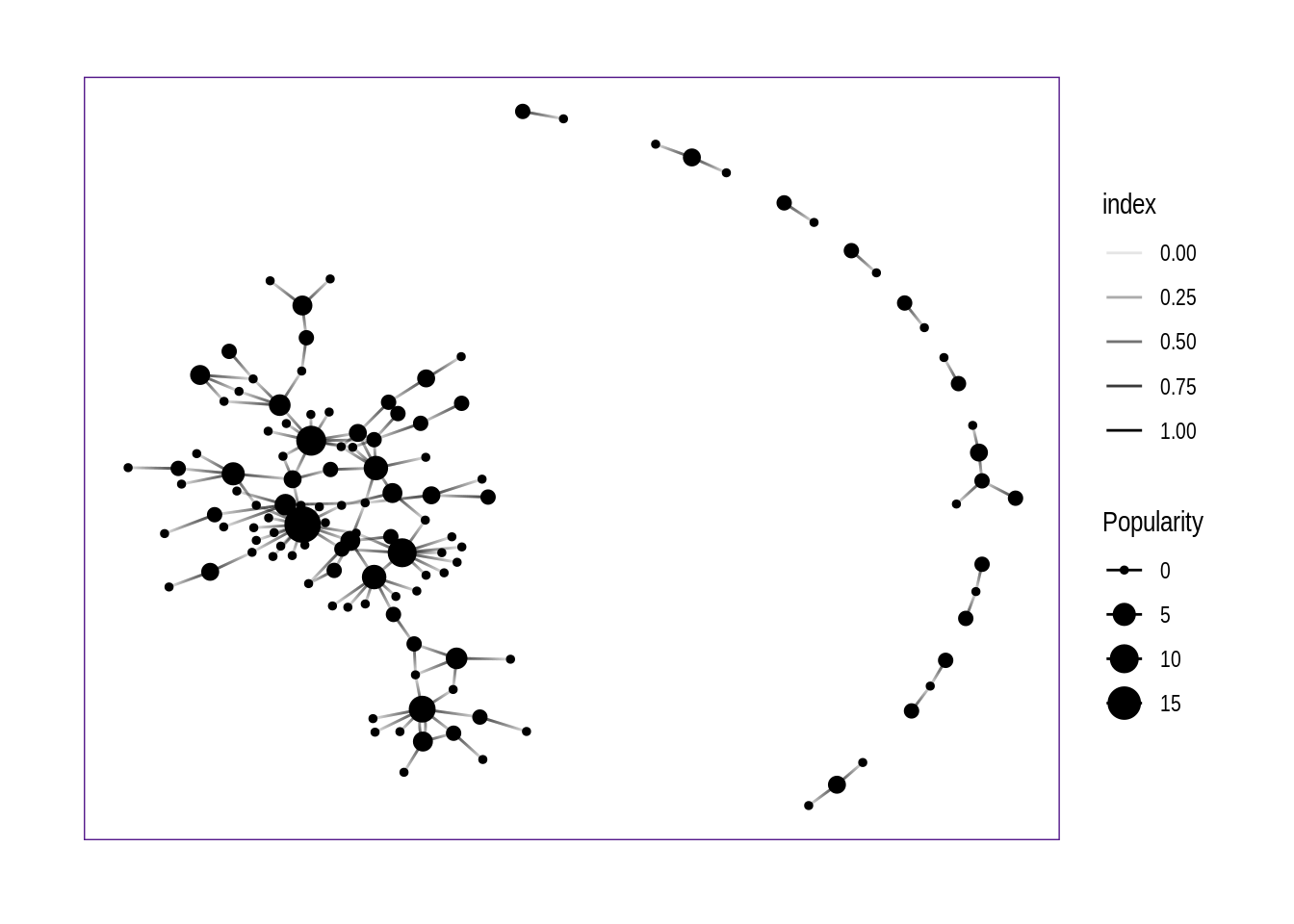
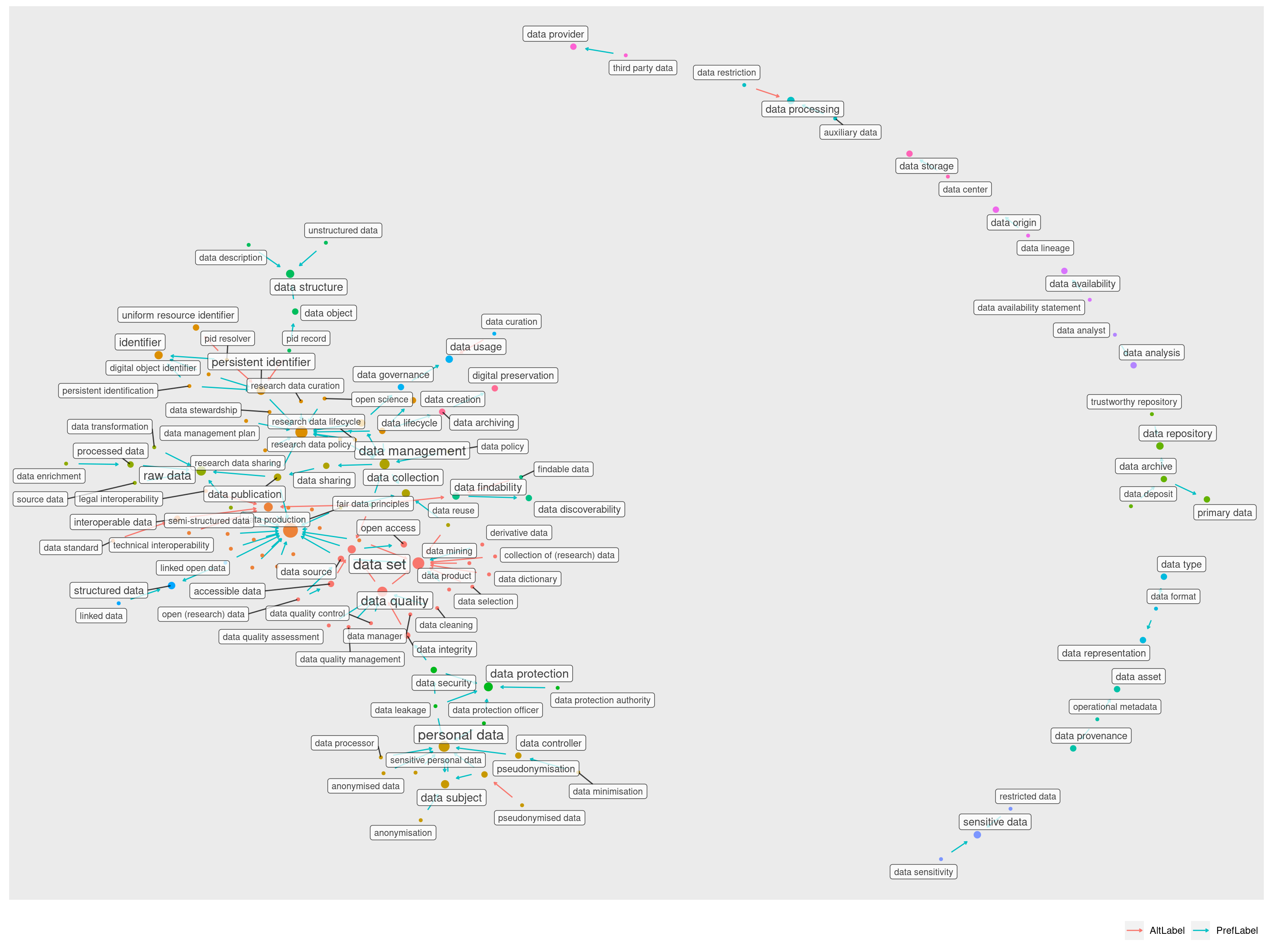
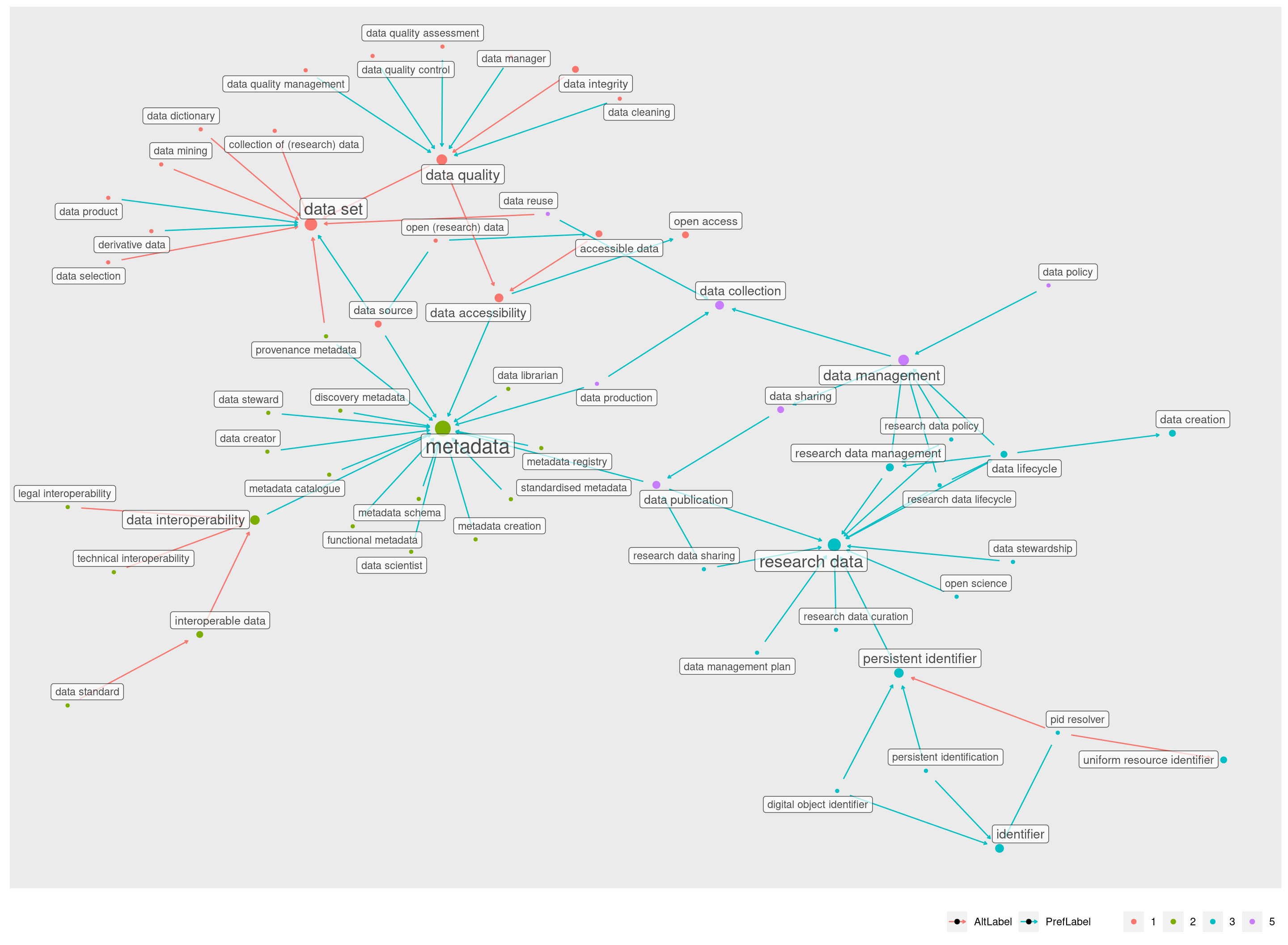
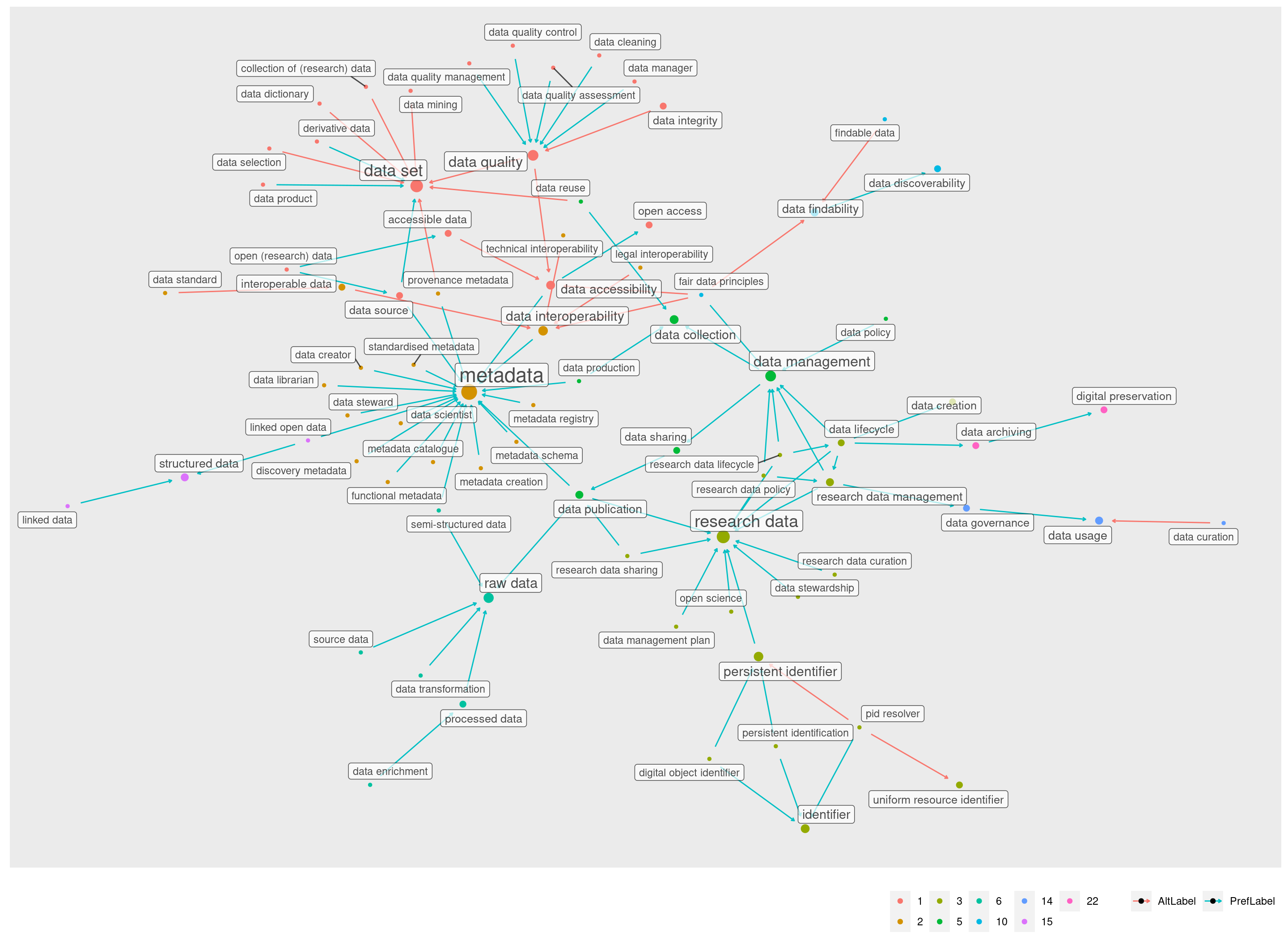
A primeira informação que logo vemos aqui é que há um aglomerado principal, do lado esquerdo, e apenas alguns aglomerados menores, unindo no máximo cinco termos.
Entre estes conjuntos menores temos um com 5 elementos, 4 com 3 elementos e outros 5 com 2 elementos cada.
Ao tentar adicionar os nomes de cada nó, percebi que a quantidade de texto é enorme e fica pior ainda se adicionamos os nomes das conexões:
A visualização acima usa um efeito de densidade para representar as áreas de acordo com relações por PrefLabel ou AltLabel. É possível ver aqui que as PrefLabels (azul) predominam por todo o grafo, à exceção da área ao redor do nó data set.
Na verdade, a única AltLabel para “data set” é “dataset”. Se observarmos mais de perto, podemos perceber que a maioria das relações para “data set” ocorrem por sua AltLabel e não pelo nome principal:
Vamos usar o geom geom_node_label no lugar de geom_node_text para ter um fundo branco em nossas labels e usar a propriedade repel = TRUE para evitar tantas sobreposições.
O resultado é bem mais legível, mas ainda não é apropriado para uma pequena área de visualização. Nesta página, estamos usando toda a área disponível e mesmo assim a visualização é difícil. O gráfico está poluído e não é possível discernir a que cada label se refere.
Vamos separar um pouco mais, retirando os conjuntos menores.
Clusterização
A visão geral pode ser interessante, mas é mais apropriada para visualizações interativas que possam ser arrastadas e usar de recursos como zoom e a exibição dinâmica dos nomes dos nós — ao tocar ou passar o mouse em cima, por exemplo. Esse processo será abordado na seção 5.
Para continuar a análise, vamos criar clusters, ou seja, conjuntos menores de nós onde poderemos focar.
As bibliotecas que lidam com estruturas de dados como grafos fornecem recursos úteis para manipular e segmentar esses dados, encontrando subgrupos dentro deles e separando suas relações. Um desses recursos é a possibilidade de automaticamente encontrar quais são as “comunidades” de nós, ou seja, quais nós possuem mais proximidade dentro da rede.
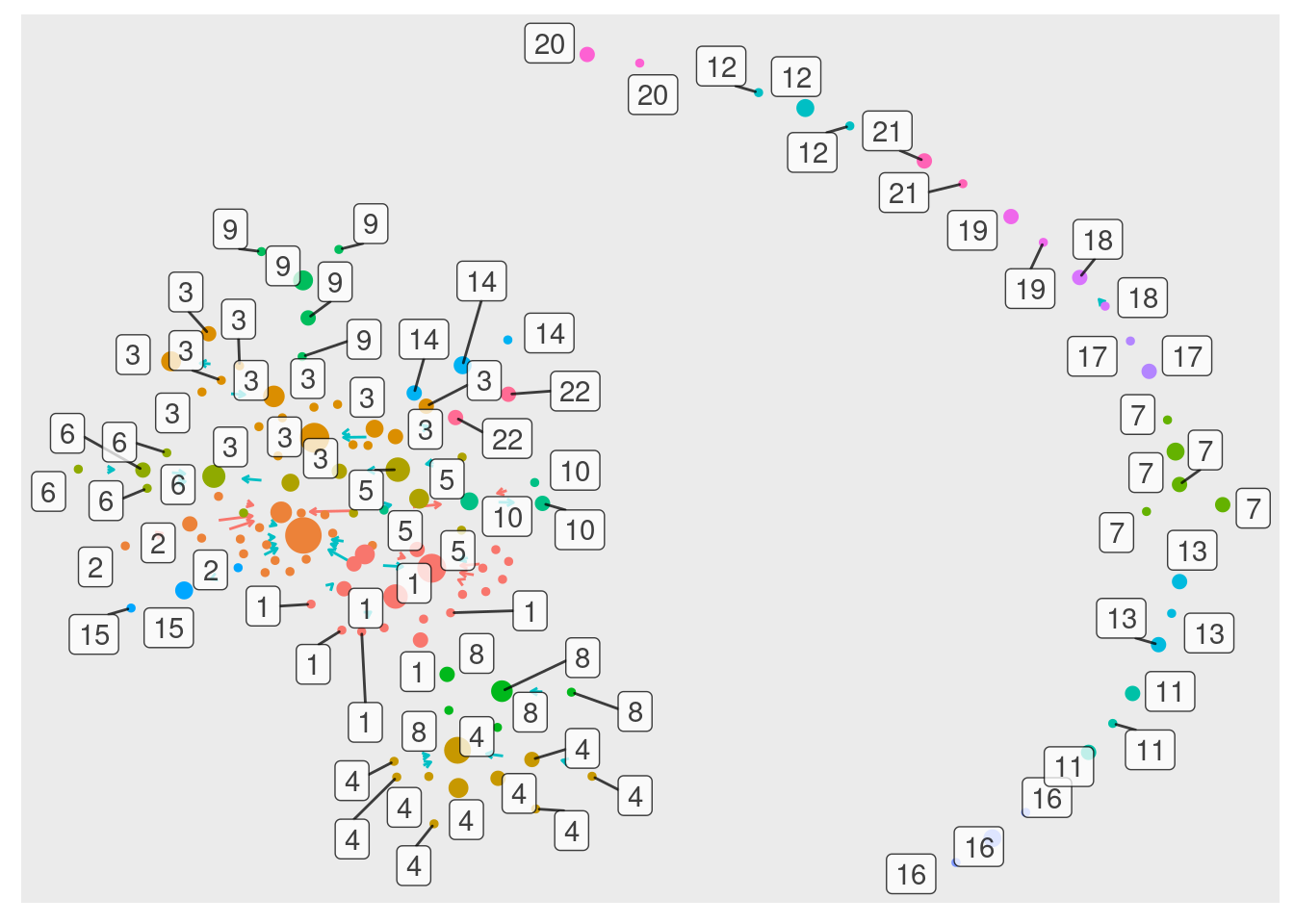
Vamos gerar um novo gráfico que exiba numericamente as comunidades nas labels:
Agora que temos as comunidades bem definidas visualmente, vamos incluir os valores de popularidade no conjunto principal para podermos extrair algumas informações sobre a métrica:
E podemos ver também quais são os níveis existentes de popularidade:
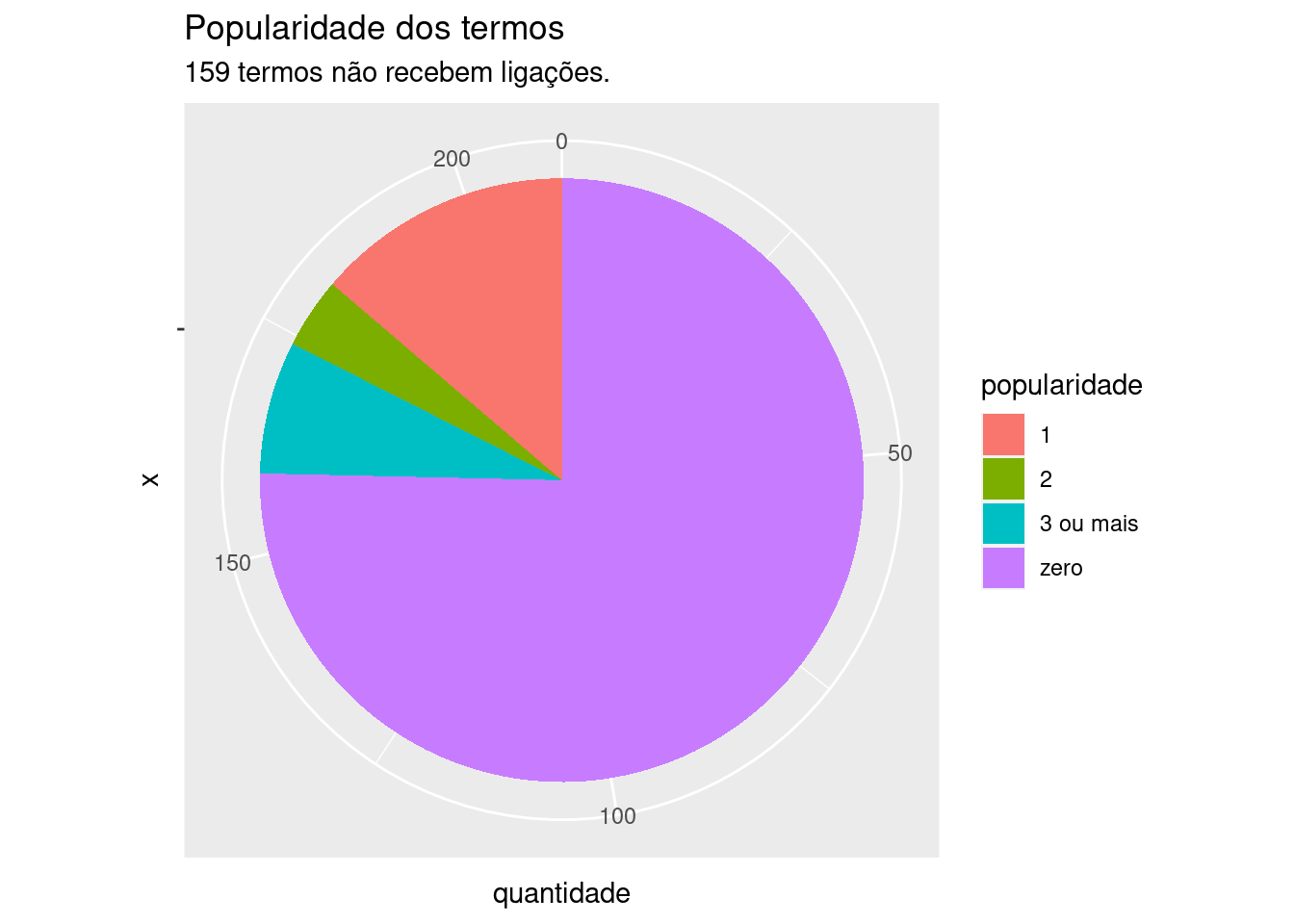
table(termos$Popularity)
0 1 2 3 4 5 6 8 10 11 19
159 29 8 5 3 1 2 1 1 1 1
A grande maioria dos termos (159) tem popularidade zero. 29 termos recebem apenas uma ligação e 8 recebem duas. Os demais termos, que recebem 3 ou mais ligações, juntos são apenas 15.
Também podemos representar isso da seguinte forma:
Código
data.frame(popularidade =c("zero", "1", "2", "3 ou mais"),quantidade =c(159, 29, 8, 15)) %>%ggplot(aes(x ="", y = quantidade, fill = popularidade)) +geom_bar(stat ="identity", width =1) +coord_polar("y", start =0) +labs(title ="Popularidade dos termos", subtitle ="159 termos não recebem ligações.")
Podemos também saber qual é a popularidade média:
mean(termos$Popularity)
[1] 0.6492891
Ou a popularidade média entre termos com popularidade acima de zero:
Popularity
Min. : 1.000
1st Qu.: 1.000
Median : 1.000
Mean : 2.635
3rd Qu.: 3.000
Max. :19.000
A popularidade média quando acima de zero é de 2.635.
Com base nesses dados, abaixo foi desenvolvida uma relação de quais seriam possíveis nomes para cada categoria a partir dos nós mais relevantes em cada comunidade.
A tabela está ordenada da maior à menor popularidade e limita-se à amostra do cluster principal.
Comunidade
Nó
Popularidade
2
metadata
19
3
research data
11
1
data set
10
4
personal data
8
5
data management
6
2
data quality
6
6
raw data
5
2
data interoperability
4
8
data protection
4
3
persistent identifier
4
1
data accessibility
3
5
data collection
3
9
data structure
3
4
data subject
3
3
identifier
3
10
data findability
2
Categorização
Se você veio até aqui pelo atalho e gostaria de saber o que significam termos como nó e popularidade, pode encontrar uma explicação na seção 1.
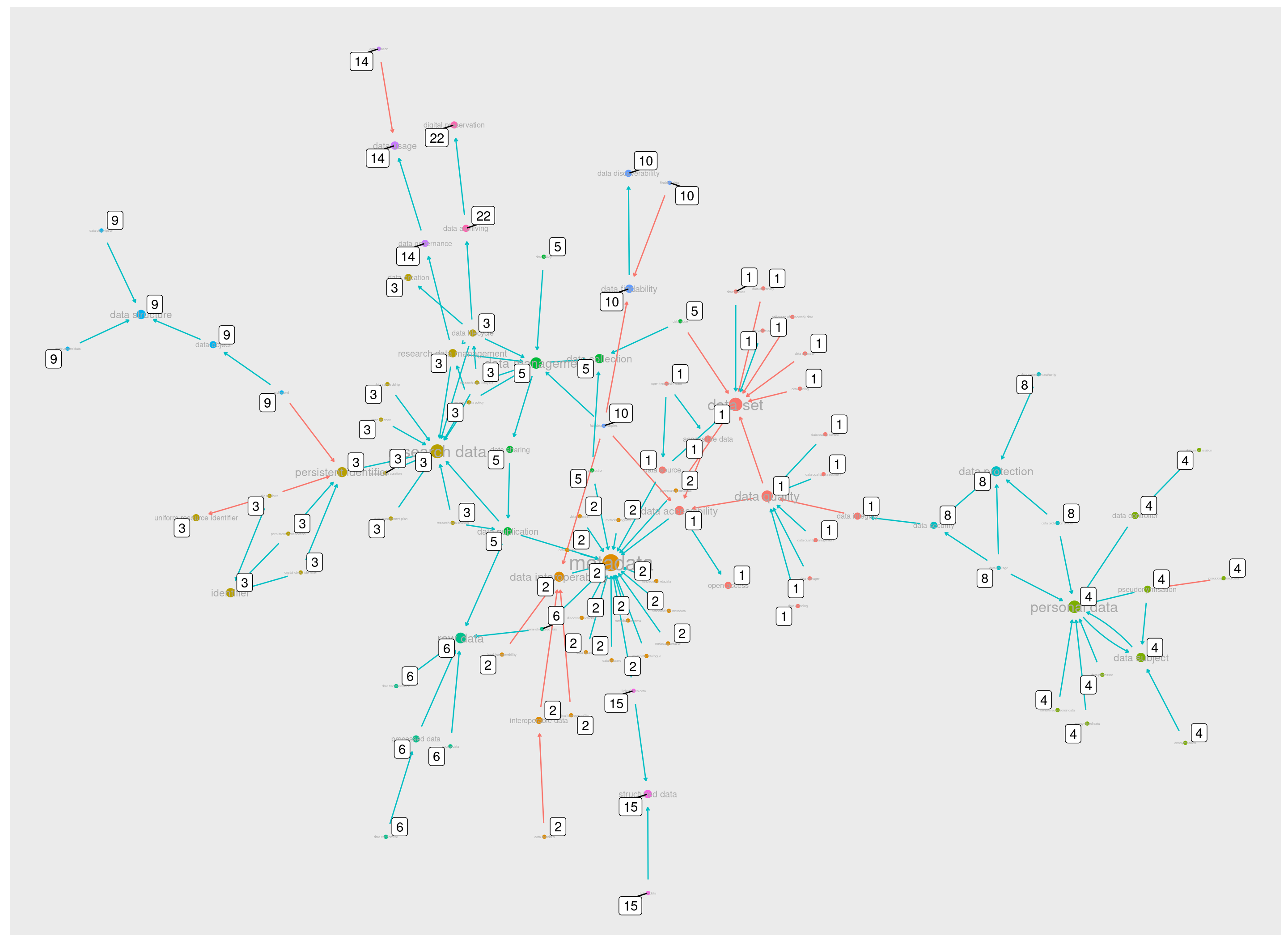
Em nossa amostra principal estão contempladas todas as comunidades de 1 a 10, com exceção da comunidade 7, que não conecta-se ao cluster principal.
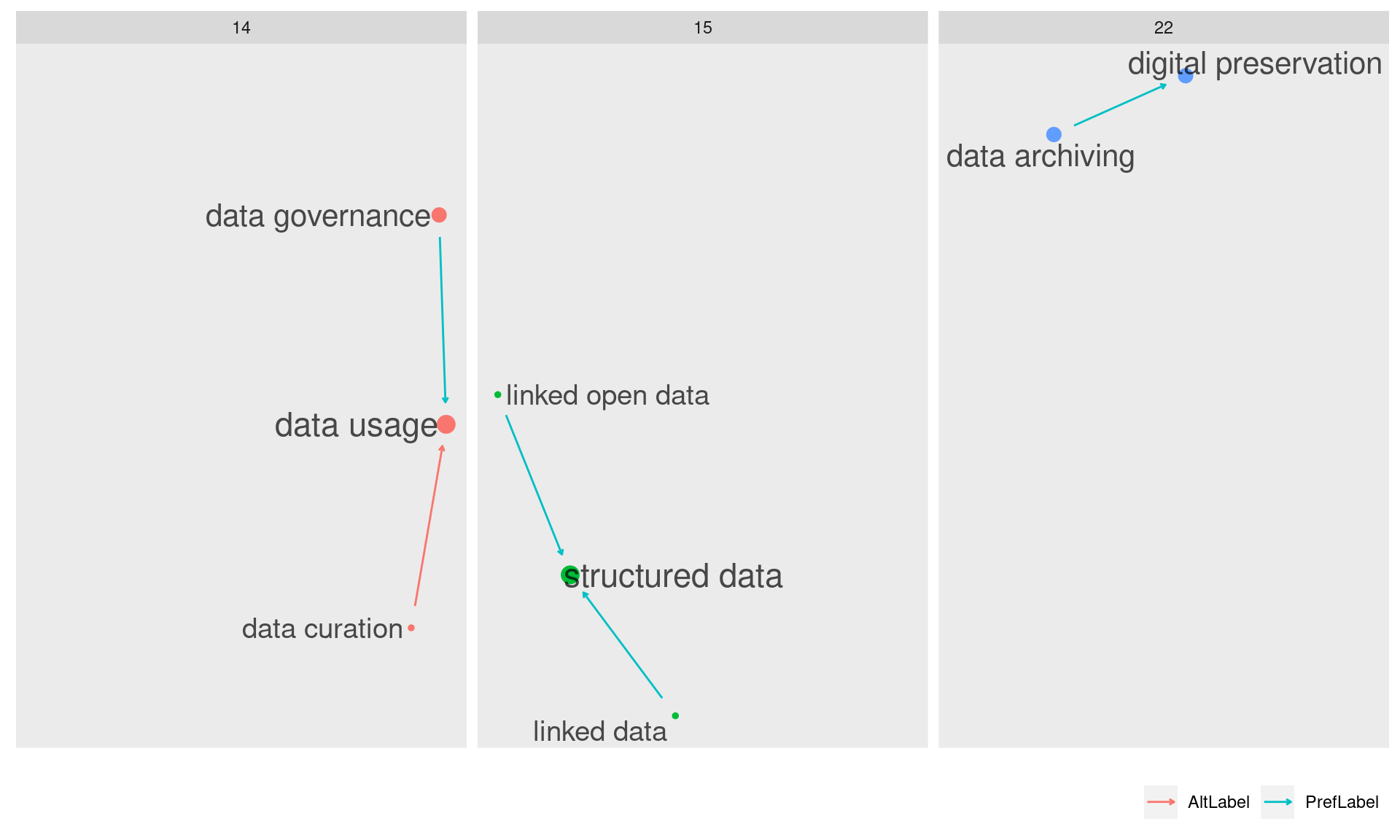
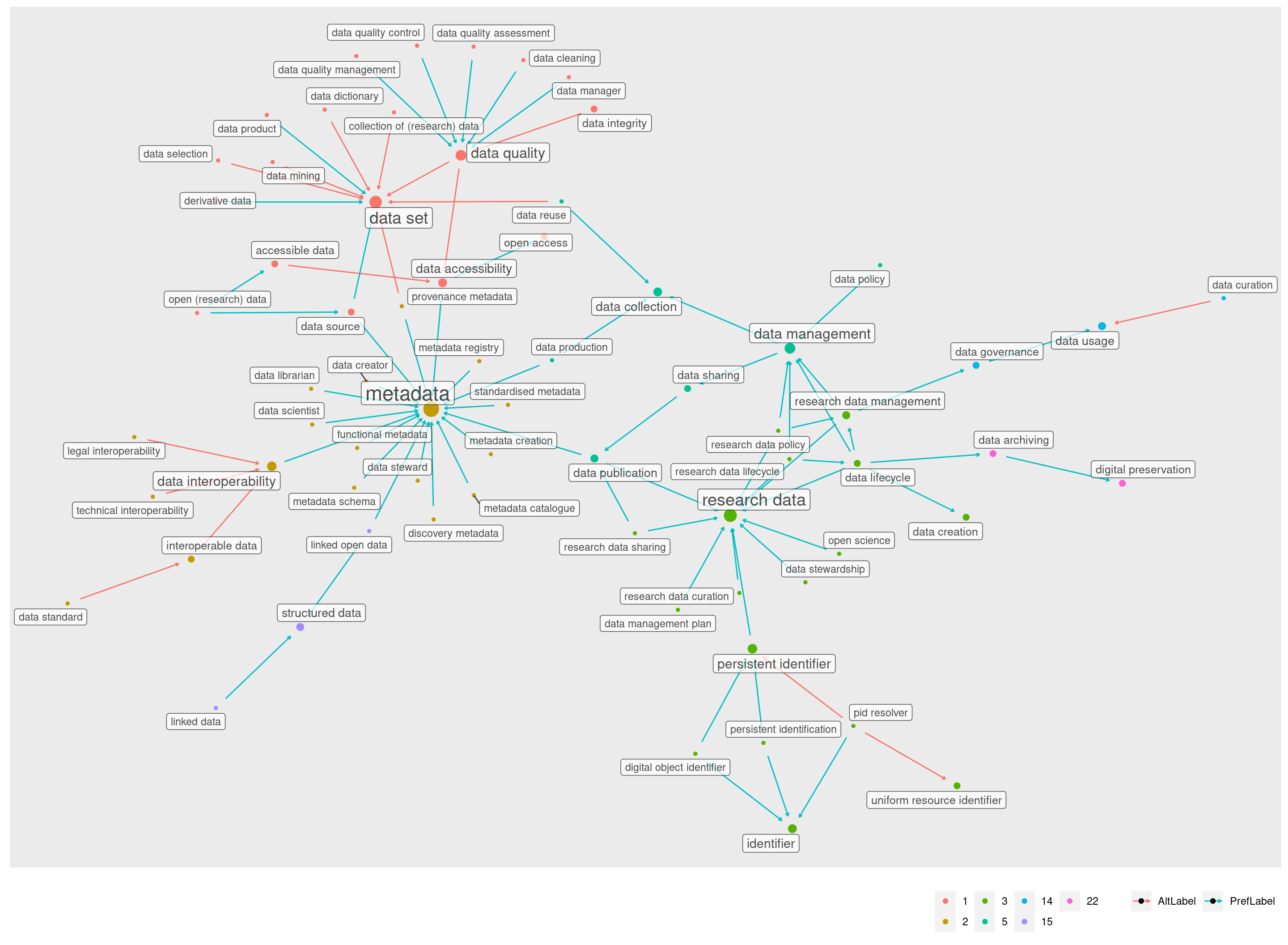
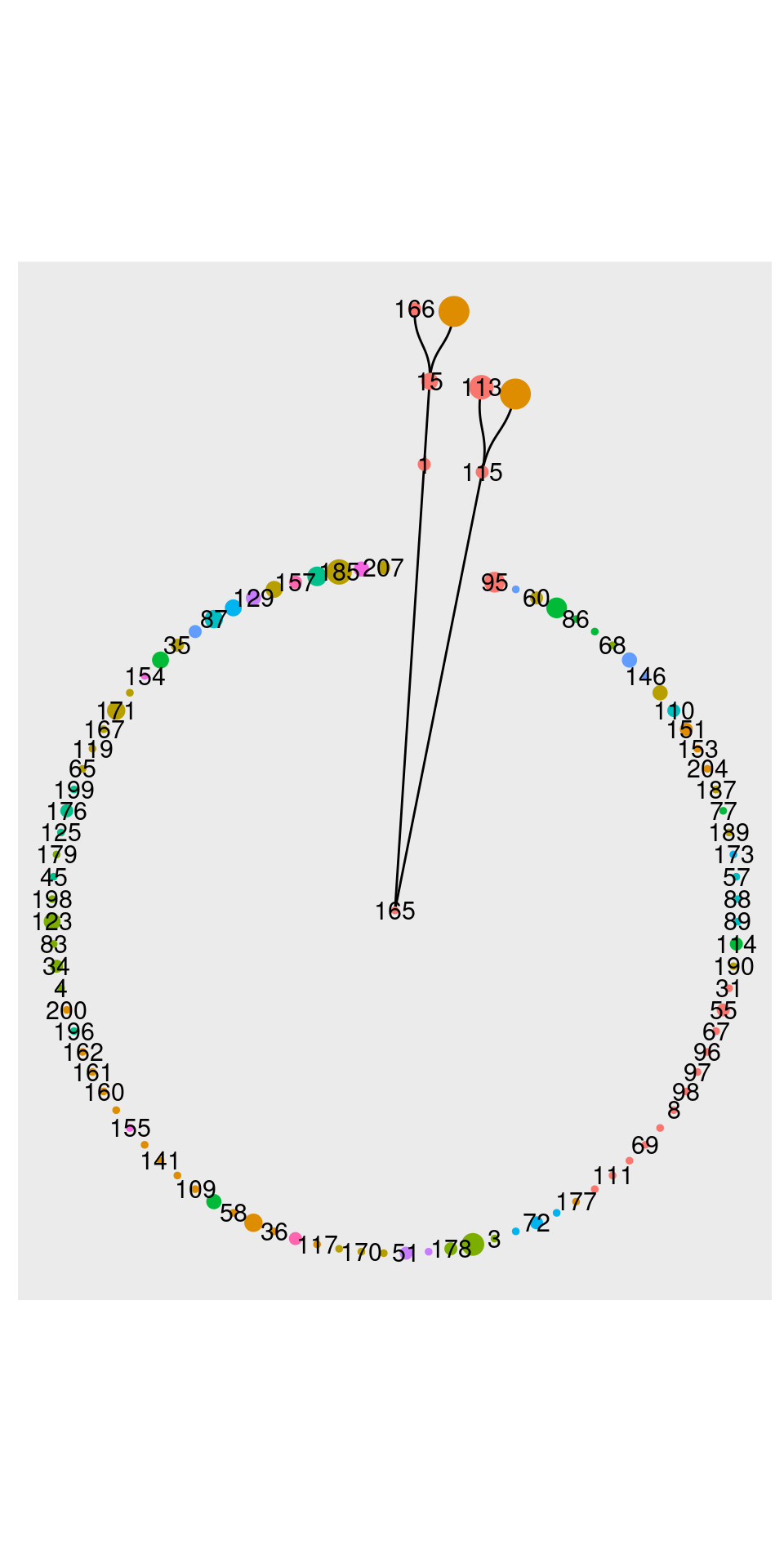
Além destas 9 comunidades, que são as maiores e mais populares, restam ainda três comunidades menores: 14, 15 e 22.
Na visualização acima, podemos ver que a comunidade 14 tem como ponto mais externo “data governance”. Esse termo faz a ponte para os demais de sua comunidade.
O mesmo acontece com “data archiving”. Se este termo não fosse mencionado por “data lifecycle”, a comunidade seria outra das que ficaram excluídas do cluster principal.
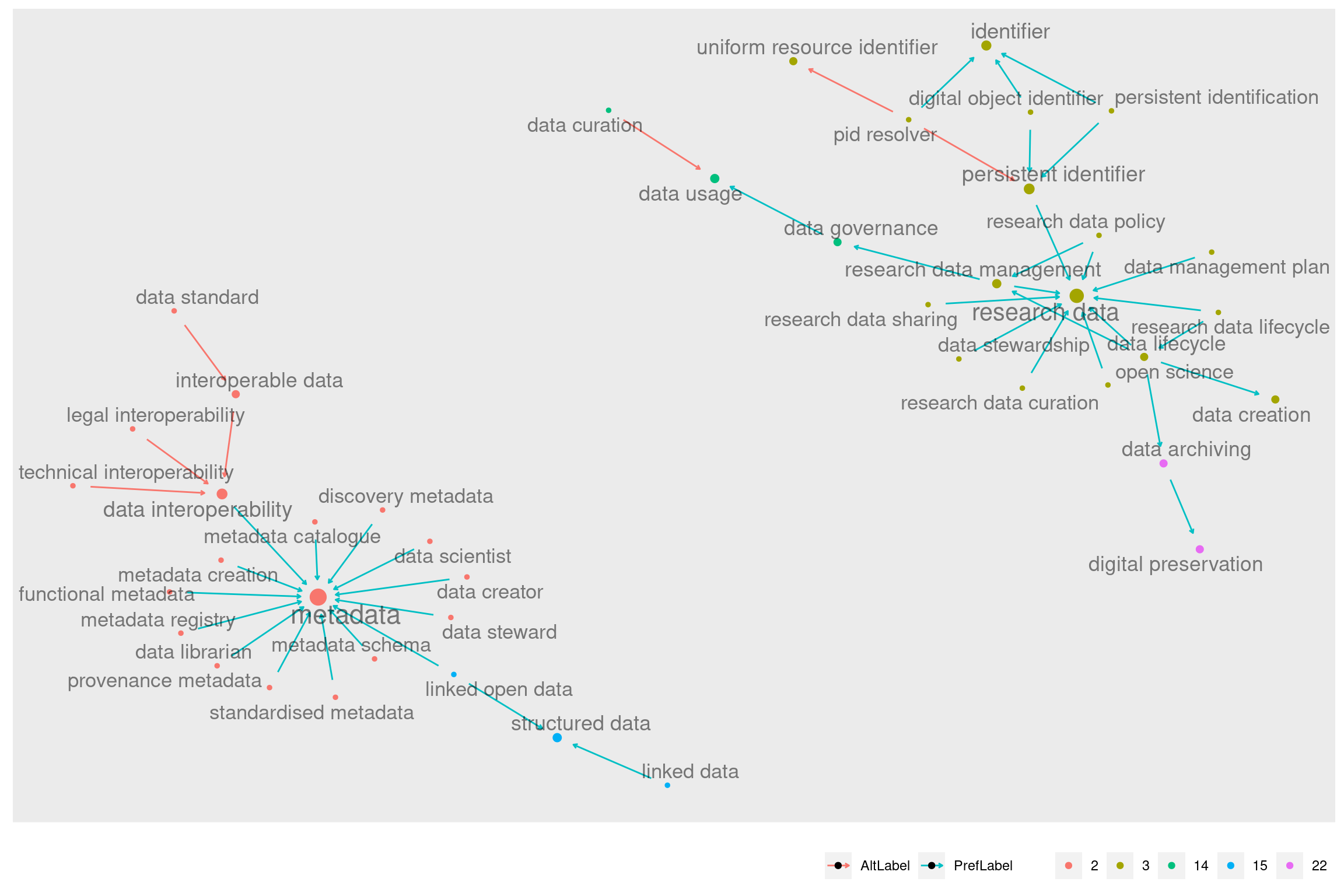
Já a comunidade 15 está mais próxima da comunidade 2, metadata. Ela aparece abaixo em azul, na parte inferior do gráfico:
A visualização acima mostra as três comunidades menores, 14, 15 e 22, junto de suas vizinhas maiores, o cluster metadata (número 2, em laranja, abaixo) e o cluster research data (número 3, em verde, acima).
Outro fato visível nesta visualização é como a comunidade 5 representa um ponto nevrálgico entre quase todas as principais comunidades. Sem ela, a comunidade 3, research data, uma das três maiores, ficaria isolada das duas outras.
Podemos confirmar isso na visualização abaixo, inclui todas as comunidades do cluster principal exceto a comunidade 5:
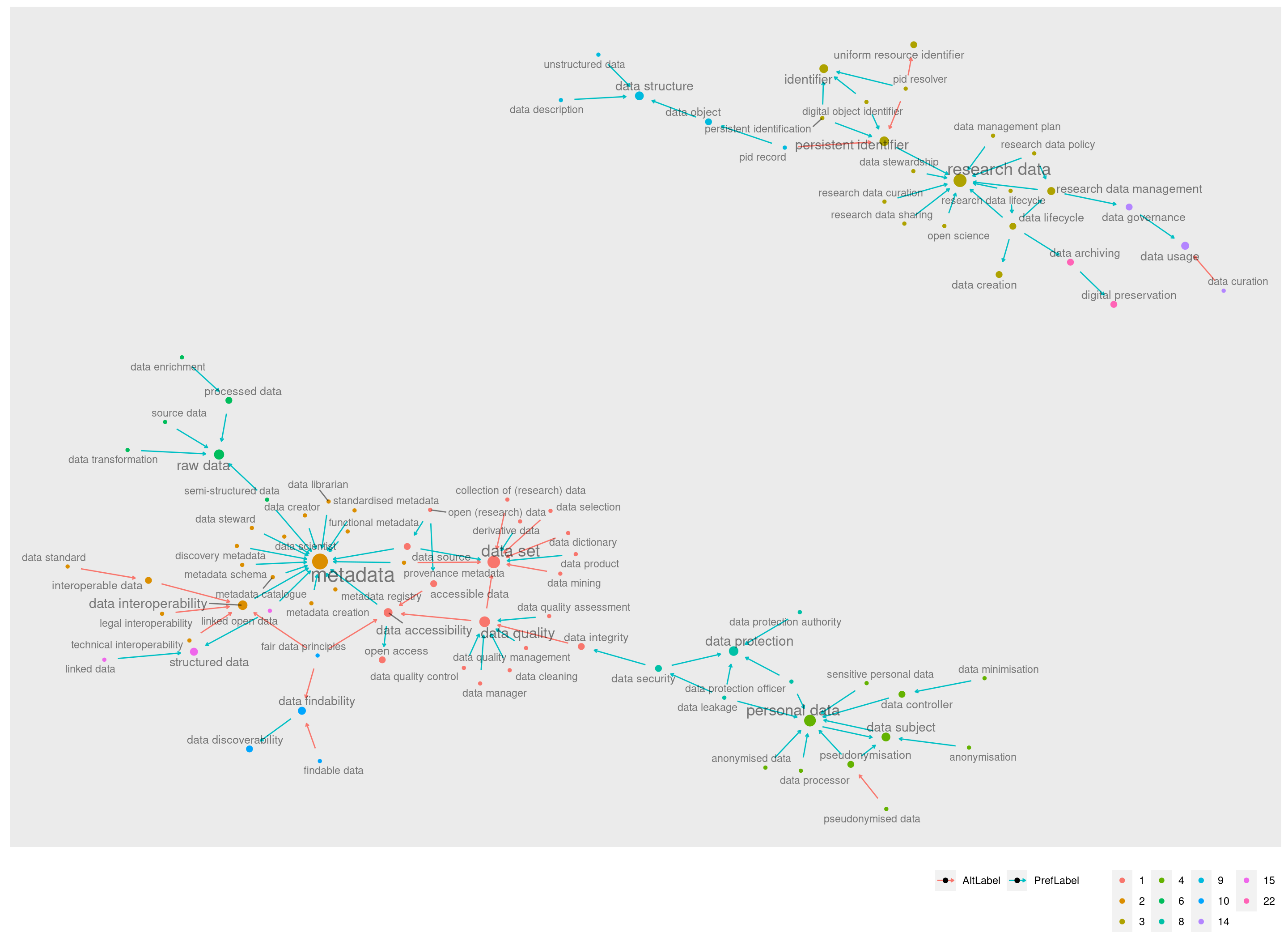
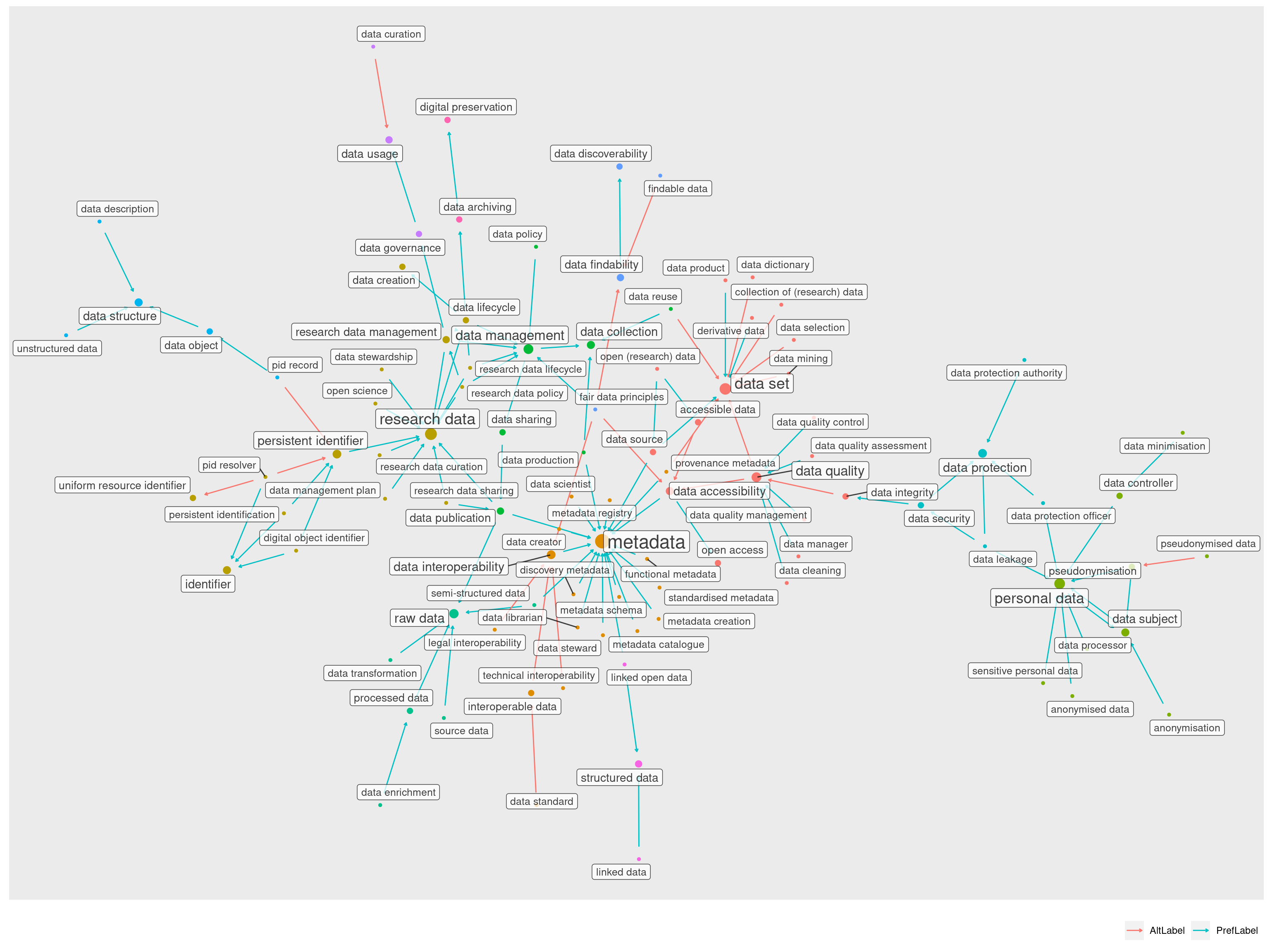
Juntando portanto todas as comunidades centrais, com as quatro maiores e suas imediações formadas pelas pequenas comunidades (2, 6, 10, 14, 15, 22) temos um grafo já bastante recheado:
Restam apenas as comunidades, 4, 8 e 9 que formam as bordas esquerda e direita do cluster principal.
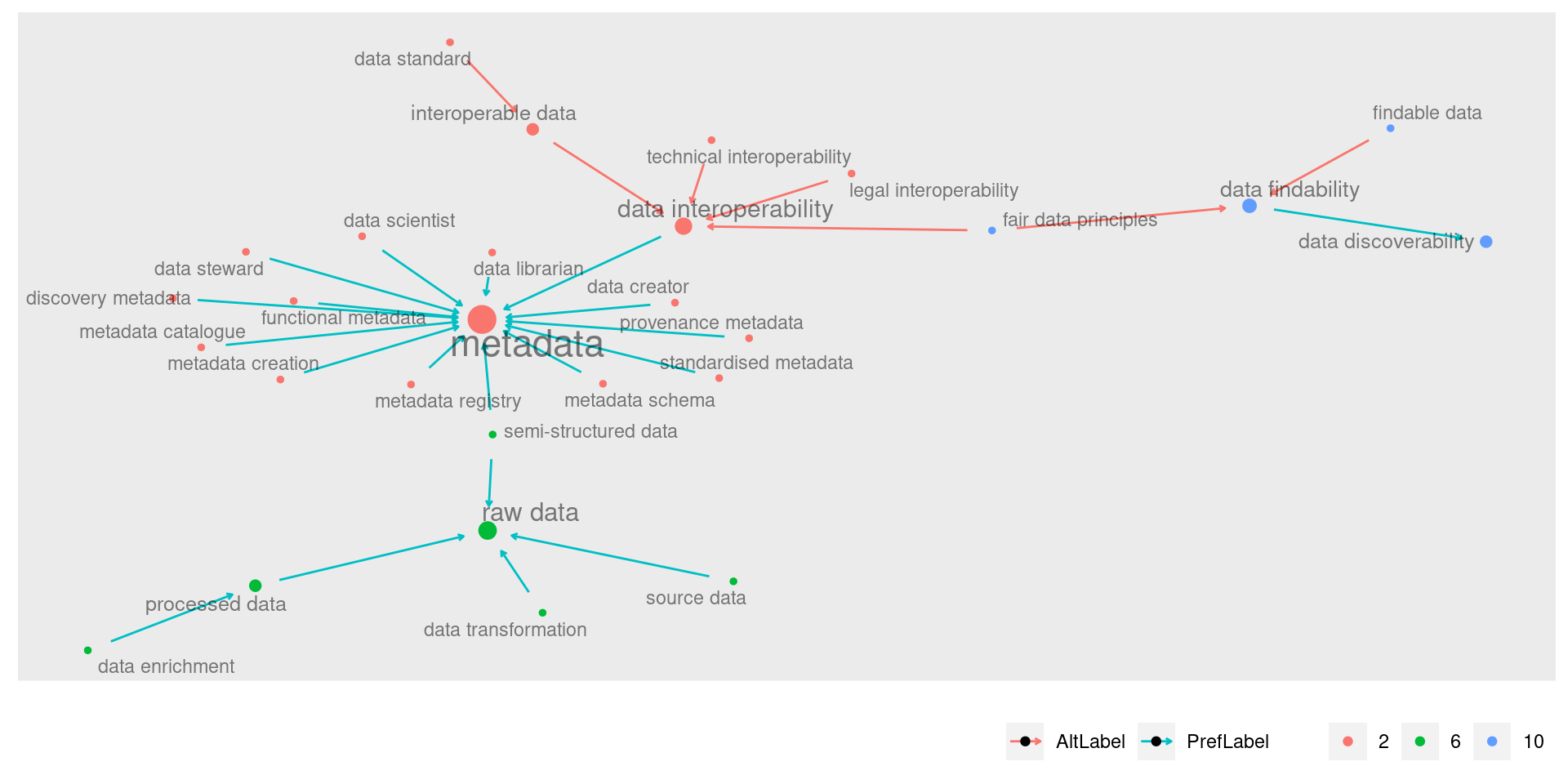
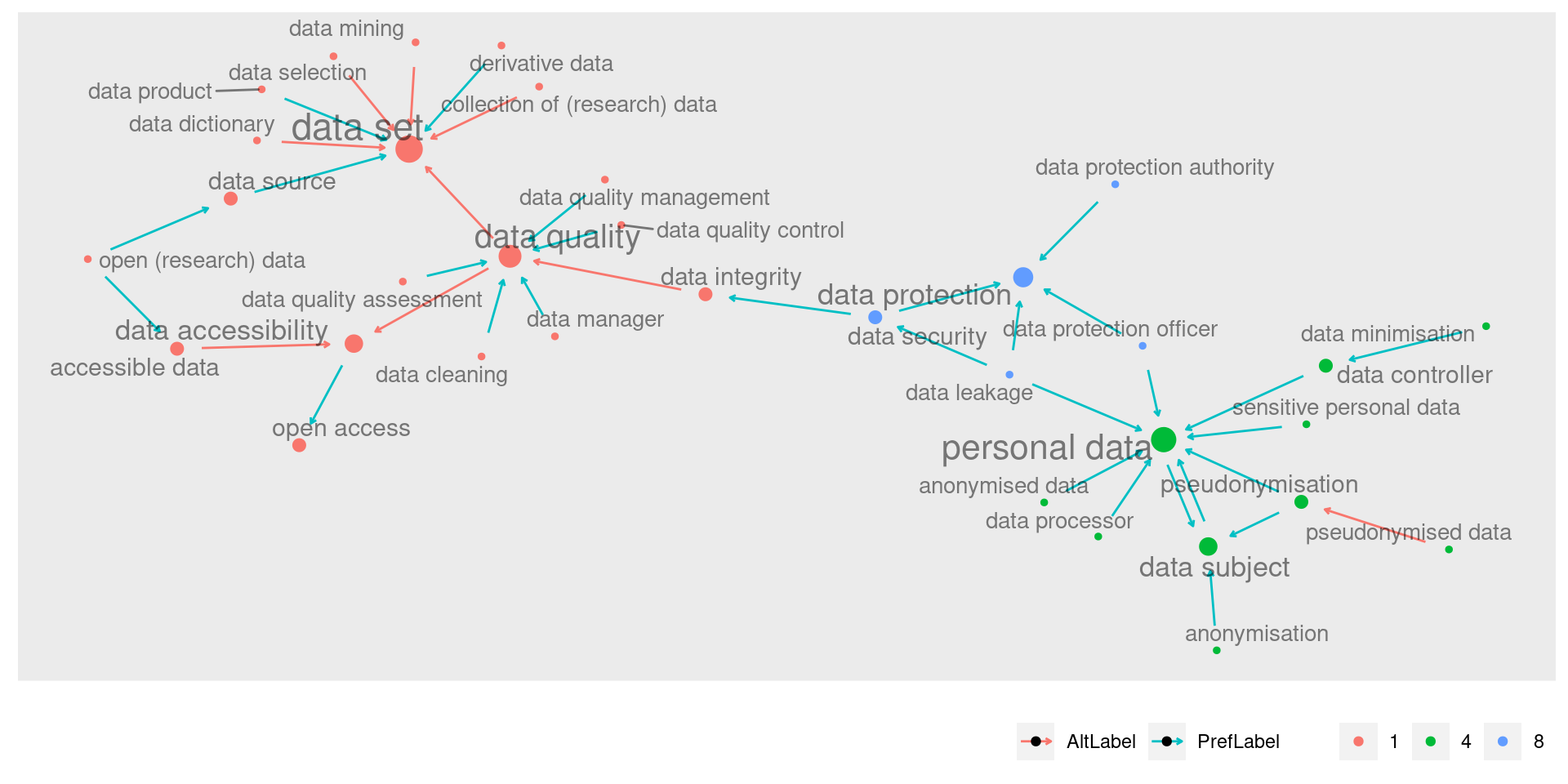
As comunidades 4 e 8 são muito próximas, e falam sobre a proteção de dados e o sujeito de dados. Elas possuem relações entre si, independentemente de outros conjuntos.
Sua ligação com o cluster principal não é através do cluster metadata, mas sim do nó “data security” (da comunidade 8) que se conecta ao nó “data integrity” do cluster data set:
Este é um de meus recortes preferidos. Ele mostra um caminho significativo que vai de “dados pessoais” para “proteção de dados” e que então faz uma ponte que passa por “segurança” e “integridade de dados” para só então desaguar no conjunto principal.
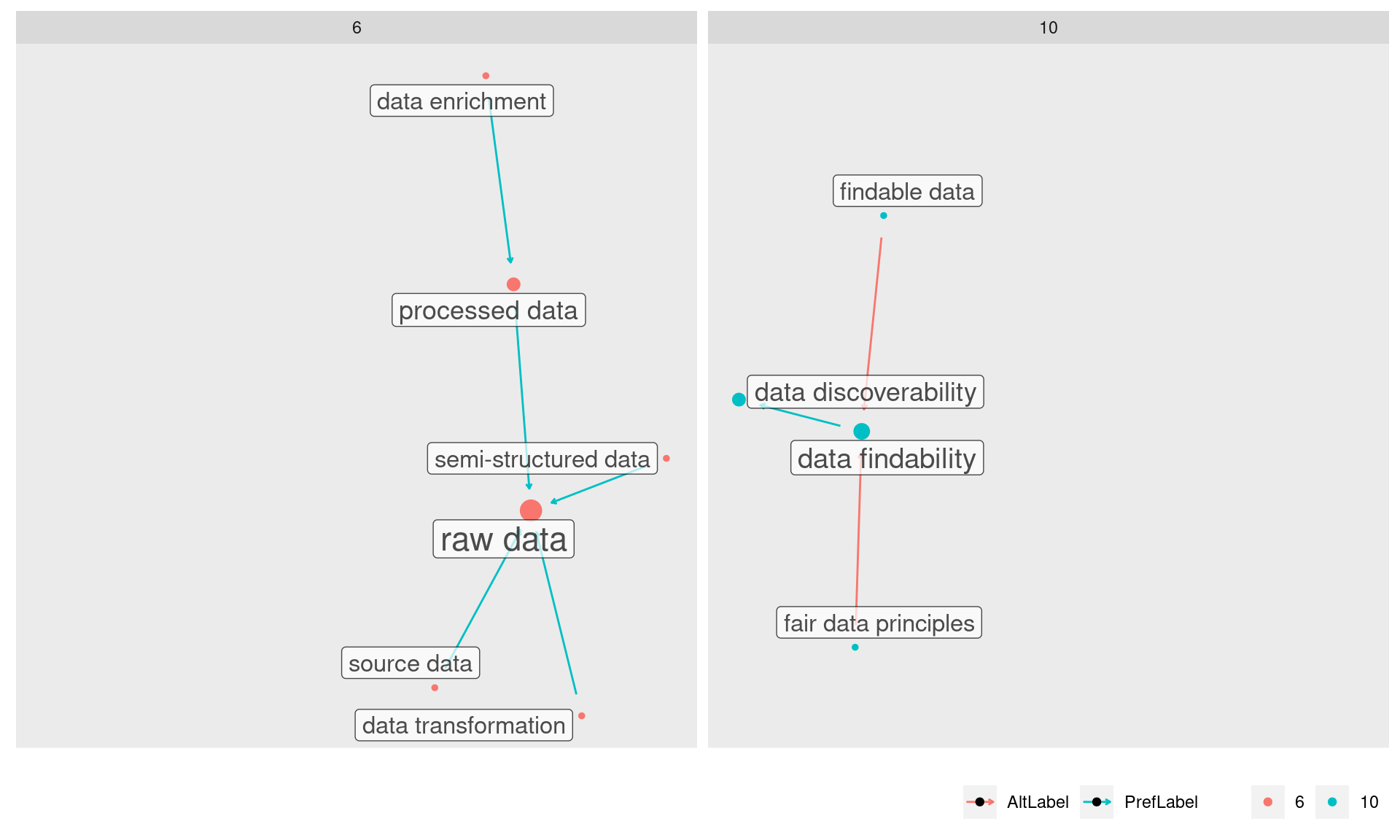
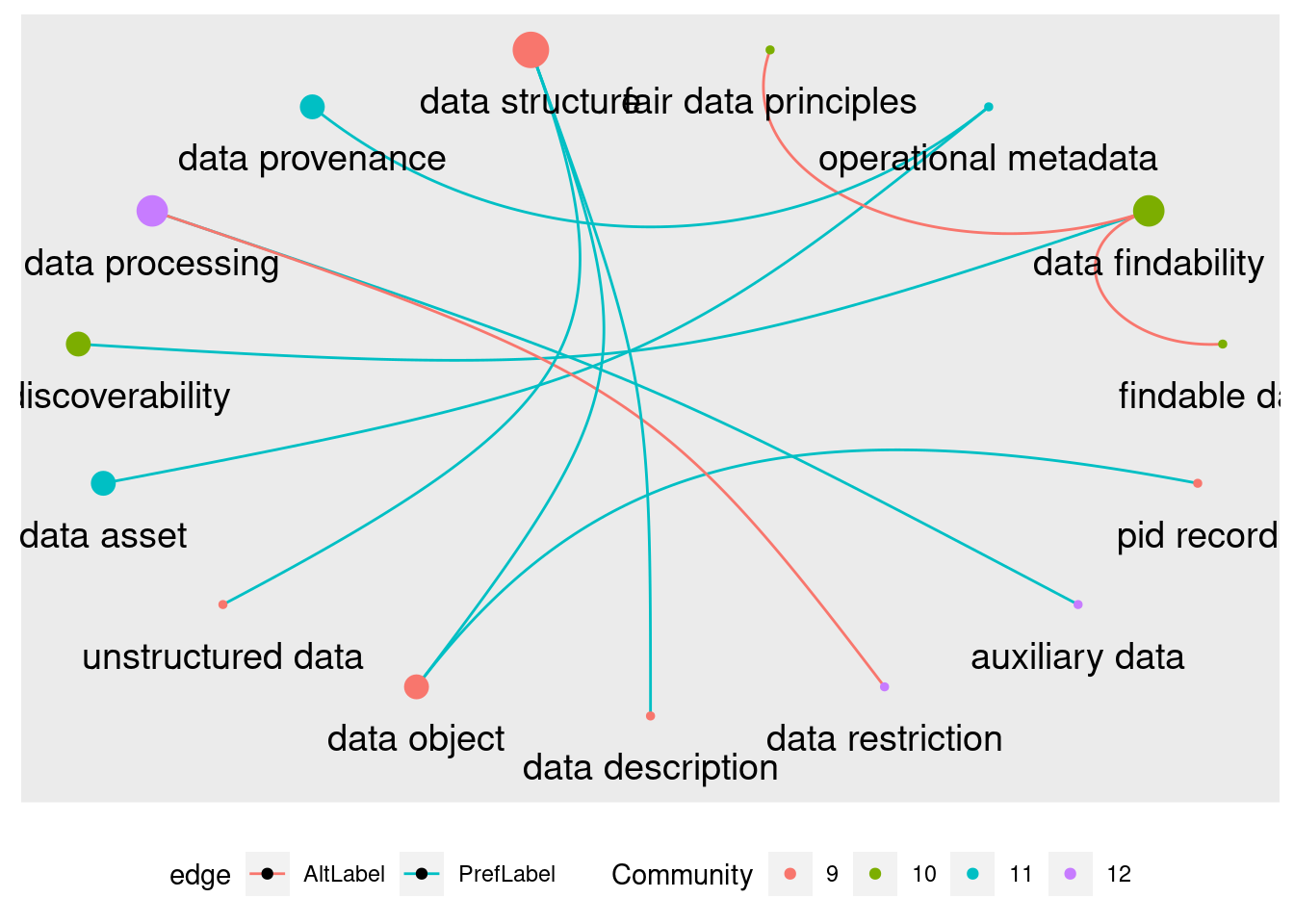
Por fim, no outro extremo do grafo, no lado esquerdo, temos a pequena comunidade 9, que orbita ao redor do nó “data structure”:
Os dados aqui contam a história de uma viagem por diferentes campos semânticos. Temos termos que pertencem a um mesmo contexto, a gestão de dados, mas que têm diferentes níveis de proximidade.
No começo, parti com o objetivo de determinar quais termos tinham mais relevância. Ficou bastante evidente que termos como metadados e data set são bastante importantes para podermos compreender inúmeros outros, ou seja, eles são componentes importantes para explicar e precisar o vocabulário de dados.
Outro termo de grande destaque também foi personal data, que aparece com importância para explicar ideias relacionadas à proteção de dados. Esse termo gerou uma das relações entre comunidades mais semanticamente significativas.
Visualizações como essa podem exemplificar o poder de pensar os termos não só por suas repetições mas especialmente por suas relações e como essas relações os agrupam. É justamente o nó “segurança de dados” que faz a ponte externa desse conjunto para o cluster principal.
Apesar de não terem grande popularidade, esses termos que realizam pontes, mencionando ou sendo mencionados por outros termos fora de suas comunidades, também poderiam ser pensados como tendo importância específica na análise de relações em linguagem natural, já que sem eles teríamos uma rede semântica mais dispersa.
Ao pensar em análise de definições, a menção de um termo implica não somente conexão ou relevância mas uma possível necessidade daquela palavra para conseguir definir outro termo.
Numericamente, esses foram os resultados finais da métrica de popularidade:
Para pessoas que se interessam ou trabalham com o processamento de linguagem natural, ou que precisam determinar a importância de diferentes conceitos para estudar ou ensinar sobre eles, o mapeamento de relações semânticas pode ser uma ferramenta bastante didática.
Como última etapa, gostaria ainda de explorar a possibilidade de navegar interativamente por este grafo após ter mergulhado nele por algum tempo. Essa intenção surgiu após as primeiras plotagens, pois durante todo o processo muitos gráficos acabam poluídos demais pelo texto que identifica cada ponto.
Bibliotecas para visualização interativa de grafos permitem que o texto identificador apareça apenas quando interagimos com um determinado nó.
networkD3
A biblioteca networkD3 usa uma estrutura de dados parecida, mas com dataframes separados para edges e nodes.
É necessário ainda diminuir todos os IDs em 1 pois a biblioteca é baseada em um framework JavaScript que usa indexação a partir de 0, ao contrário da R.
Na renderização acima é possível dar zoom e arrastar a visualização. Os nomes são exibidos ao tocar ou clicar sobre um nó e é possível ainda movimentá-los.
visNetwork
A última biblioteca, visNetwork, oferece a possibilidade de exibir as definições completas ao interagir com cada nó.
library(visNetwork)
Para trabalhar com essa biblioteca são necessaŕios também dois dataframes distintos, um para nodes e outro para edges. O dataframe com nodes deve ter uma coluna com IDs e o de edges deve ter colunas from e to que ligam os IDs.
Outro fator é que as colunas desse dataframe podem ser usadas para passar suas propriedades estéticas.
Este formato é de difíci visualização com tantos nós inclusos. Aqui também está demonstrada a possibilidade de editar os nós com os controles interativos providos pela biblioteca.
Para pessoas interessadas na gestão de dados, a análise dessa amostra sugere que termos como metadados, interoperabilidade de dados e proteção de dados são especialmente relevantes para definir outros termos.
Grupos como dados pessoais, dados de pesquisa, qualidade de dados e gestão de dados, além de estarem entre os mais populares, agem como agregadores e fazem importantes pontes entre as diferentes áreas do grafo.
Outros termos altamente populares não foram destacados neste último resumo acionável por terem um papel mais passivo como objetos da gestão de dados: conjunto de dados e dados brutos.
Apesar de estar disponível em diferentes idiomas, o português não era uma das contempladas pelo Multilingual Data Stewardship Terminology. Seria possível, porém, cruzar dados de fontes compatíveis que possibilitariam um novo estudo de relações observando variações entre os idiomas.